
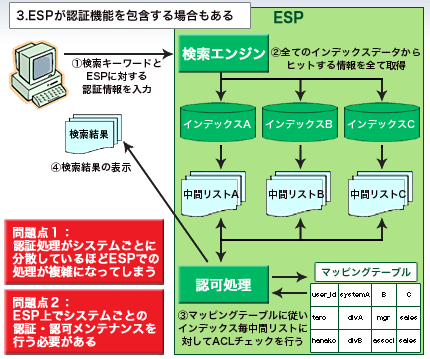
また、企業組織によっては認証基盤が共通化されておらず、情報システムごとにID管理が行われていることも多い。この場合、ESPがシステムごとのACL情報をマッピングし、認証・認可の代替〜検索処理を行うことになる。その結果ESPの処理負担は大きくなり、検索処理効率を下げることも考えられる(図2)。ESPの能力を最大限に引き出し、情報アクセス効率の向上を実現するためには、ID管理を含めた社内情報システムの整理を行うべきである。
ESPにACL機能を組み込むことで、企業内の膨大な情報の中から自分に必要な情報群を特定することが可能となる。しかし、企業のもつ情報量は爆発的に増えており、得られる検索結果リストは、利用者が期待する以上の相当量となってしまうことも珍しくはない。そこで、最終的に利用者が欲している情報が優先的に表示されるような仕組みを別途提供しなければならない。
インターネットにおける検索の多くは、キーワードに対する答えや詳細な解説を探し出すためのものである。このため、多くの検索エンジンは主にキーワードに対する適合度(どれほどその単語が含まれているか)と、該当ページのアクセス数によって情報の優先順位付けが行われ、結果上位のものからリストされる。 企業組織においてはどうだろうか。イントラネット内での検索の場合にもインターネット同様、キーワードに対する答えや解説を探す場合もあるが、CRMやSCMなどの業務システムから最新情報を入手し、それを元に何らかの判断や次のアクションを行うという使われ方も少なくない。このため、検索結果の表示に際して、「情報の最終更新日時」が優先順位の高い要素となるだろう。
また、利用する業務プロセスによって対象となるシステムを絞り込み、得られた検索結果について業務ごとに分類することも必要となるだろう。多くの検索エンジンでは、インデックスデータをシステムごとに作成するが、これらのデータがどの業務プロセスで利用されるかの分類情報までは設定されない。 検索エンジンの中には、インデックスデータを選択できるようなAPIを公開して、EIPなどの他システムに組み込んだり、利用者に選択できるようなオプション機能を提供したりするなど、分類情報を外部システムに委ねることで実現しているツールもある。次世代のESPでは、業務ごとにインデックスデータ同士を関連付けた分類情報までを内部に保持することが求められる。
企業内で効果的な横断検索環境を実現するためには、他システムや業務との一層の連携が必要となる。それだけに導入・運営フェーズでの既存環境やデータの整備が必要となってくるが、詳細は次回以降での解説としたい。
みずほ情報総研 システムコンサルタント 平古場浩之





