協調フィルタリング技術を掘り下げる--ECサイトのレコメンド技術を考える(3) |
前回は、ECサイトのレコメンド技術の種類として、ルールベース方式、コンテンツベースフィルタリング方式、協調フィルタリング方式、ベイジアンネットワーク方式の4つを紹介した。今回は、これらのレコメンド方式をより細分化した上で、協調フィルタリングのロジックについて解説したい。
4つのレコメンド方式は、「レコメンドするために必要な情報は何なのか」、「何をもってレコメンドするためのルールとするか」という切り口で分類していると解説した。それぞれのレコメンド方式は、さらに「どの判別属性を軸にレコメンドアイテムを決定しているのか」という切り口によって細分化できる。その判別属性とは、アイテムベース、ユーザーベース、ユーザー提示情報ベースの3つだ。
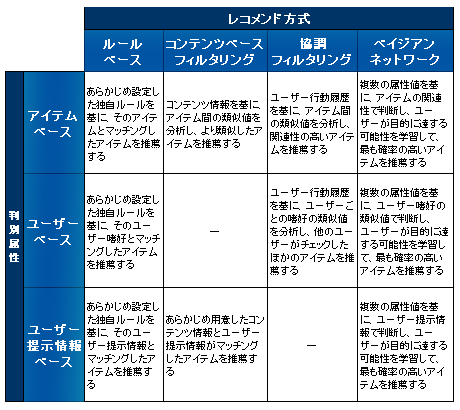 図1:レコメンド方式と判別属性
図1:レコメンド方式と判別属性例えば、データマイニングや統計解析を得意とするブレインパッドの「Rtoaster」は、ウェブアクセス履歴を基に同社がデータマイニングを行い、独自のルール設定をするルールベース方式である。あらかじめ設定しているルールに加え、ウェブアクセス履歴でユーザーがどこから流入したか、どのページをよく見ているかといったユーザー行動を判断材料とし、レコメンドアイテムを決定している。つまり、「ブログサイトから来た人にはこの商品」といった、特定のユーザー行動に対して特定のアイテムをレコメンドする、ルールベース方式とユーザーベースを組み合わせたレコメンド機能である。
また、アルベルトの「Bull's eye」は、アイテムごとの情報をデータベース化して、ユーザーが直接入力した情報に近いアイテムを表示する。これは、コンテンツベースフィルタリング方式とユーザー提示情報ベースを組み合わせたレコメンド機能だ。ユーザーのあいまいなニーズを、店員とやりとりしていくように入力し、理想に近い商品を表示する。この手法は、アルベルトの運営する消費者支援サイト「教えて!家電」で使用されている。
このように4つのレコメンド方式は、3つ判別属性によって分けられる。ただし、コンテンツフィルタリング方式は、ユーザーが選んだアイテム情報もしくはユーザーが入力したアイテム情報を利用するため、ユーザーベースの判別属性は利用しない。また、協調フィルタリング方式は、ユーザーの暗黙的なユーザー行動履歴情報を利用するため、ユーザー提示情報ベースの判別属性は利用しないことになる。
一方、ここで本題となる協調フィルタリングは、アイテムベースおよびユーザーベースという判別属性によって細分化できることがわかる。協調フィルタリング×アイテムベースは、ユーザーの行動履歴を基にアイテム間の関連性を分析し、あるアイテムを表示した時に関連性の高いアイテムを表示する方式だ。もうひとつの協調フィルタリング×ユーザーベースは、ユーザーの行動履歴を基にユーザーごとの嗜好の類似値を分析し、嗜好の似たユーザーがチェックした他のアイテムを推薦する方式である。
筆者が所属するケイビーエムジェイの「パーソナライズド・レコメンダー」は、連載第1回でも述べたECサイトの目標である「ユーザーにより多くの商品を見てもらい、より多くのユーザーをコンバージョンに結び付ける」という命題を実現するため、協調フィルタリング×アイテムベースを採用している。その詳細なロジックとアイテムベースを採用する理由について、これから詳しく説明しよう。
協調フィルタリング×アイテムベースのロジックとは
まず、ユーザーの暗黙的なユーザー行動履歴情報を取得するために、ウェブビーコン(ウェブページに埋め込まれた情報収集用の極めて小さい画像)を設置する。例えば、商品c の商品購入完了ページにウェブビーコンを設置すると、ユーザーAが商品c を購入した際に表示される商品購入完了ページの表示履歴が購入履歴としてデータベースに蓄積される。この繰り返しで蓄積される情報を基に、図2のようなクロス集計が作成される。
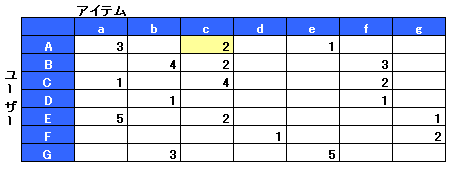 図2:ユーザーと商品の購入履歴のクロス集計
図2:ユーザーと商品の購入履歴のクロス集計協調フィルタリング×アイテムベースの基本処理を概念的に説明すると、4段階のクロス集計プロセスを経てルールを作成することになる。これを図解すると図3のようになる。
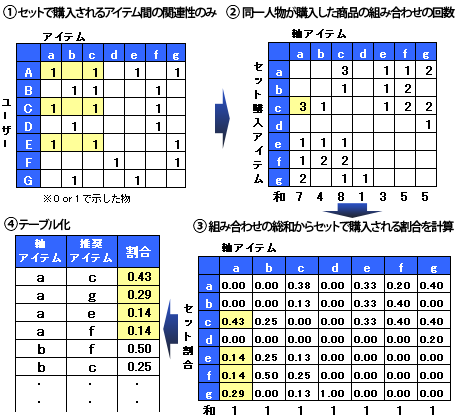 図3: 協調フィルタリング×アイテムベースの基本処理概念図
図3: 協調フィルタリング×アイテムベースの基本処理概念図処理の1段階目では「セットで購入されるアイテム間の関連性のみ」を集計するため、商品ごとの購入回数は無視し、一度でも購入があった場合を「1」に、全く購入がなかった場合を「0」に変換する。図3の?を見ると、商品a と商品c をセットで購入した人は、ユーザーA、ユーザーC、ユーザーEの3人だとわかる。
2段階目は、「同一人物が購入した商品の組み合わせの回数」を集計する。図3の?のように、軸アイテムとなる商品a と、その商品とセットで購入した商品c との組み合わせ回数は3回だとわかる。このように2段階目は、軸アイテムとセット購入アイテムをクロス集計し、アイテム間の関連性を分析する。
3段階目は、「組み合わせの総和からセットで購入される割合を計算」する。そして、4段階目にこの割合をテーブル化することにより、「商品a を購入した人に対して商品c を43%、商品g を29%、商品e を14%の割合でレコメンドする」というルールが作成される。これが協調フィルタリング×アイテムベースの基本処理の流れだ。
協調フィルタリング×アイテムベースの課題と対策
協調フィルタリング×アイテムベースを採用するレコメンド機能は、こうした基本処理をベースに開発されているが、この方法には以下のような課題がある。
- セットで購入するケースが少ない場合、レコメンドされない、またはレコメンドの精度が悪くなる
- レコメンドされるアイテムが人気の高いアイテムに偏る
- レコメンドされるアイテムが長期間掲載しているアイテムに偏る
- 同一アイテムに対する連続的な閲覧や、クローラーなどの閲覧によって偏る
- 関連性のないカテゴリのアイテムがレコメンドされてしまう
- 自動計算では意図的なレコメンドができない
これらの課題を改善するために、各社のレコメンド機能は、基本処理に加え、精度を向上するためのロジックを導入している。わが社のパーソナライズド・レコメンダーでは、ユーザー行動履歴情報の嗜好抽出方法や、さまざまな切り口による重み付けで精度を向上している。パーソナライズド・レコメンダー特有のロジックについては次回解説しようと思う。
なぜアイテムベースなのか
さて、ここでパーソナライズド・レコメンダーがアイテムベースを採用している理由について解説しよう。それは、ECサイトに訪れるユーザーの利便性と、ASPサービスとしての運用を考慮したためである。
協調フィルタリングは、判別属性をユーザーベースとしたケースを基に解説されることが多いが、それは、文字通りユーザー個人の行動履歴を活用したレコメンドを実現できるからである。しかしケービーエムジェイは、ユーザーベースでは前述した協調フィルタリングの欠点を回避することが困難で、ECサイトが必要とする機能としては適切でないと考えている。
図3の?「セットで購入されるアイテム間の関連性」と同様のデータから、ユーザーベースを採用した場合の基本処理を概念的に図解すると図4のようになる。
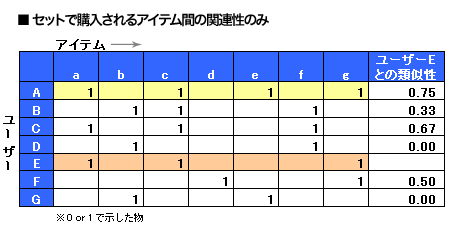 図4: 協調フィルタリング×ユーザーベースの基本処理概念図
図4: 協調フィルタリング×ユーザーベースの基本処理概念図ユーザーベースの基本処理では、このデータから、ユーザーEと類似性の高い嗜好を持つユーザーを見つける必要がある。ここでは、「ユーザーEとの類似性」を「購入履歴の一致回数÷ユーザーの購入回数」で簡易的に算出する。そうすると、ユーザーAが最も類似性の高い嗜好であることがわかり、ユーザーEにレコメンドすべき商品は、商品e だということがわかる。そして、ユーザーごとの嗜好データを保有し、個別に照らし合わせる処理が発生し、膨大なデータ量を管理する必要がある。
この基本処理における大きな問題点として、下記の3点が挙げられる。
- 他人に頼まれたものや、数年に一度しか購入しないものを購入した場合、当面そのユーザー嗜好データを基にレコメンドされてしまう
- アイテムベースとは違い、ユーザーごとのデータ蓄積を必要とする。初回訪問者は、ユーザー嗜好データがないため、レコメンドされない
- アイテムベースに比べてデータ量が膨大でデータ管理コストもかかるため、低価格なASPサービスに適さない
これに対しアイテムベースでは、大多数のユーザー行動履歴を基にアイテム間の関連性を分析しているため、例えレアな商品を購入したとしても、レコメンドに影響することがほとんどない。また、初回ユーザーでも他のユーザーと同様のレコメンドが可能となるほか、データ量を商品ごとの関連性に抑えることでコスト削減を図り、低価格のASPサービスを安定的に供給できる。これが、協調フィルタリング×アイテムベースを採用している理由だ。
次回は、パーソナライズド・レコメンダーで導入されている「協調フィルタリング課題解決方法」について解説しようと思う。
筆者紹介
高島理貴(たかしま まさき)
ケイビーエムジェイ インターネットプロダクト&マーケティング事業部 プランニング&コンサルティング グループ アクセス解析チーム チームリーダー Newビジネス企画 担当。埼玉県生まれ。年間総計30億ページビュー以上のサイトを解析し、クライアントのサイトの成長をお手伝いするアクセス解析コンサルタント。