
ビッグデータならではの領域とは
ビッグデータが生きる領域 矢野経済研究所作成
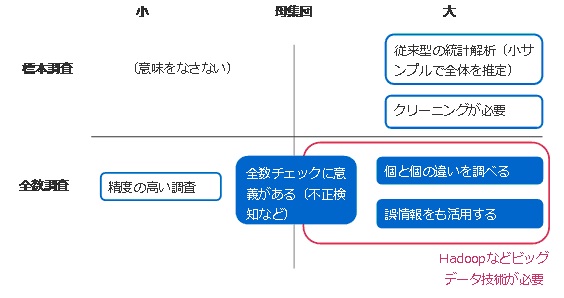
上図は、「2013 解析・分析ソリューション市場の展望 -ビッグデータ時代の注目市場-」から抜粋したものである。横軸に母集団の大きさ、縦軸に標本調査と全数調査とで分類したマトリクスである。この表をもとにデータ量と統計解析の関係を簡単に説明したい。
結論からいえば、右下に注目してほしい。これまで統計解析では、無作為抽出により、小さいサンプルサイズから精度良く、効率良く分析することが重要なポイントだった。全数調査は膨大なコストを必要とするため、小さいサンプルサイズから高い精度で母集団の傾向を分析することは非常に価値があることであった。
ビッグデータが変えたのはここだ。ビッグデータでは、サンプリングをせず、全データを対象にすることができるようになったのである。これにより、無作為抽出であったり、データのクリーニングであったりというプロセスは不要になるというのである。
整理すれば、母集団が小さければ全数調査ができるが、大きくなると標本調査をせざるを得なかった。しかしビッグデータ技術を活用することで、母集団が大きくても全数調査ができるようになった、という変化である。
では、この変化には、いったいどのような影響があるだろうか。大きな母集団に対し、わざわざ全数調査を試みる価値とは、どこにあるのだろうか。これまでは標本調査で十分であったのに―。
ここではその解答として、3点を挙げている。
一つは、「個と個の違いの見極め」である。母集団が1万人として、その1万人がどのような傾向を持っているかを調べるには、サンプルを取り、何らかの調査をすればよい。従来型の標本調査だ。しかし、1万人の中のある人たちとある人たちを比較するような場合は、サンプルでは量的に不足する場合も多い。そのため、ビッグデータ技術を用いて、大量データを確保することが重要になる。




