
性能検証の方法
同検証では、Spark SQLのクエリ処理速度の基礎性能を、(1)クラスタノード数の増加に対する性能特性、(2)データ量の増加に対する性能特性の2つの観点で計測し、Apache Hive、代表的なOSSのリレーショナルデータベースであるPostgreSQLと比較した。レイテンシ(クエリ処理時間)とスループット(データ件数/クエリ処理時間)を評価指標にしている。
検証環境の構成は下図の通り。
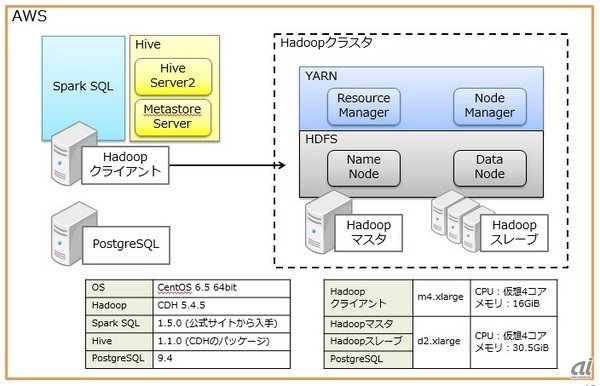
検証環境の構成
検証のためのデータとして、PostgreSQLのベンチマークツール「pqbench」を用いて「銀行の入出金取引」を想定したデータを作成。下表の「pqbench_accounts」と「pqbench_history」の2テーブルを使用した。データ量を増加させる場合は、pqbench_historyのデータ件数を増加させている。

テストデータのテーブル
クエリは、(1)SELECT、(2)SUM、(3)JOINの3種類を実行した。

実行クエリ





