
ノード数の増加に対する性能特性
クラスタノード数の増加に対する性能検証では、PostgreSQLを1ノードで固定、Spark SQLとHiveはYARN上で3種類のクエリを実行し3ノード/6ノード/9ノードで性能を計測した。
レイテンシ(秒)の測定結果を以下に示す。Spark SQLは全体的にHive、PostgreSQLより低レイテンシだった。
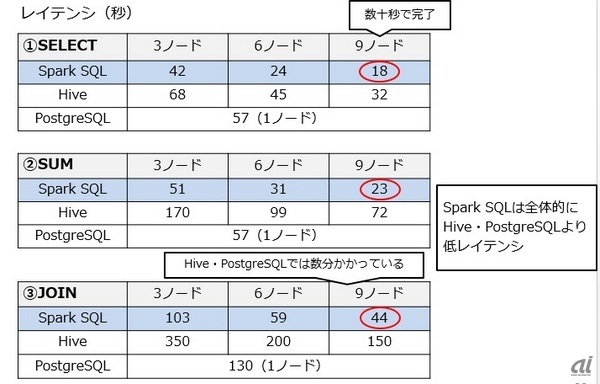
ノード数増加に伴うレイテンシ(秒)の変化
「SELECT」実行時のスループットを測定した結果は次の通り。ノード数増加に伴い、Spark SQLのスループットはほぼ線形に増加しており、Hive、PostgreSQLよりも高性能だった。

ノード数増加に伴う「SLECT」実行時のスループットの変化
「SUM」実行時のスループットを測定した結果は次の通り。ノード数増加に伴い、Spark SQLのスループットはほぼ線形に増加しており、Hive、PostgreSQLよりも高性能だった。
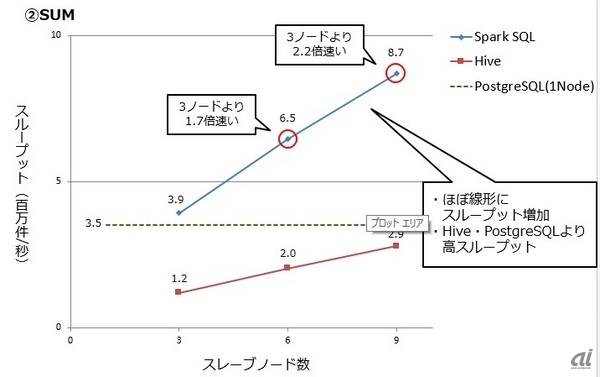
ノード数増加に伴う「SUM」実行時のスループットの変化
「JOIN」実行時のスループットを測定した結果は次の通り。ノード数増加に伴い、Spark SQLのスループットはほぼ線形に増加しており、Hive、PostgreSQLよりも高性能だった。
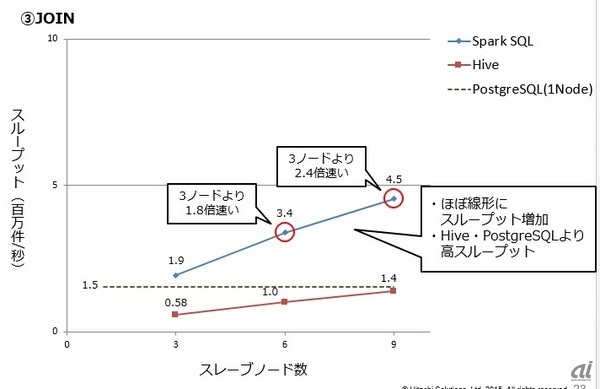
ノード数増加に伴う「JOIN」実行時のスループットの変化




