
Text Analytics APIキーフレーズ抽出機能が日本語サポート
現在プレビューとして提供されているMicrosoft Cognitive Servicesは、内部で機械学習を活用したインテリジェントな多数のAPIを提供しており、画像、動画、音声、言語処理、ナレッジ、検索といった幅広い分野をカバーしています。
言語処理関連では、現時点で日本語がサポートされていないAPIも少なからずありますが、順次対応が進められています。今回のアップデートでは、Cognitive ServicesのText Analytics API(テキスト分析API)のキーフレーズ抽出機能で、新たに日本語がサポートされました。次の画面では、Text Analytics APIのデモで、(日本語にも対応済みの)言語検出機能とキーフレーズ抽出機能の動作を確認しています。

Text Analytics APIのキーフレーズ抽出機能が日本語対応
Cognitive ServicesのAPIは単純なREST APIなので、ほぼすべてのアプリケーションから呼び出すことができますし、Microsoft Bot Framework と組み合わせて、チャットボット開発に活用するのも面白いと思います。Text Analytics API以外にも多数のAPIがあるので、是非チェックして使ってみてください。
DocumentDBの複数リージョンレプリケーション機能
Azure DocumentDBは、JSONドキュメントを格納できるドキュメントデータベースサービスです。
これまで、DocumentDBは特定のAzureリージョン(例えば、西日本リージョン)内で動作していたため、リージョン全体に問題が発生した場合などのDR(災害復旧)に懸念がありました。3月の「Build 2016」で発表し、今回GA(一般提供)となった複数リージョンレプリケーション機能を使うと、読み書き可能な1つのプライマリリージョンと、読み取り専用の複数のセカンダリリージョンを指定できるようになります。書き込みはプライマリから複数のセカンダリにレプリケーションされます。各言語向けのSDKやREST APIで新しいマルチホーミングAPIを使うことで、リージョン内のDocumentDBの障害時に、透過的に別リージョンにフェイルオーバーできます。
読み書き可能なプライマリリージョンから読み取り専用のセカンダリリージョンへのレプリケーションという構成は、Azure SQL Databaseのアクティブ地理レプリケーション機能や、Azure StorageのRA-GRS(読み取りアクセス地理冗長ストレージ)機能でも採用されている、Azureユーザーにはお馴染みの機能ですね。
DocumentDBの複数リージョンレプリケーション機能のドキュメントは、こちらだけしかなく、今後の整備が待たれる状況なので、簡単に利用手順を説明しましょう。
- Azureポータルの「新規」をクリックし、検索ボックスで「DocumentDB」を検索するなどして、「DocumentDB - Multi-Region Database Account」を選択します(ポータルのUIが日本語でエラーとなった場合には、UIを英語にしてお試しください)。
- 次に、プライマリリージョンを指定して、複数リージョンデータベースアカウントを作成します。
- 作成後は、セカンダリリージョンの追加/削除や、書き込みリージョンの優先順位(読み書き可能なプライマリリージョンの障害時にどの順番で書き込み処理をフェイルオーバーするか)の設定が可能です。
次の画面では、西日本リージョンをプライマリリージョンとしてアカウントを作成後、3つのセカンダリリージョンを追加しています。
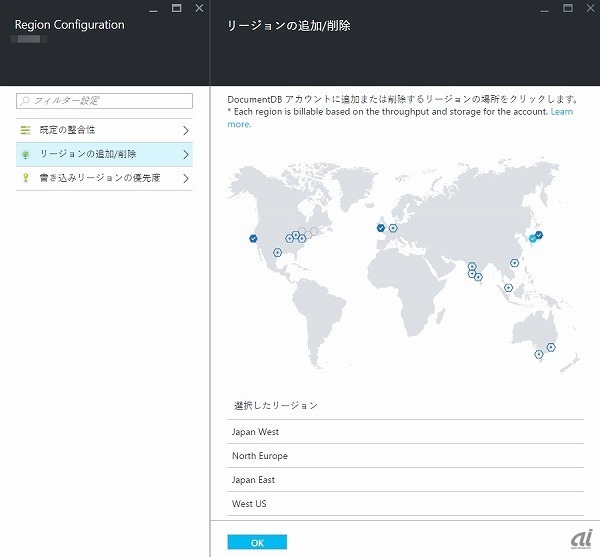
DocumentDBの複数リージョンレプリケーション機能。西日本リージョンをプライマリリージョン指定したのちに、3つのセカンダリリージョンを追加した様子




