
ビッグデータ分析やHPC向けのクラウドサービスとDocker
過去の連載でも紹介したように、あまりCPU性能やメモリ容量を必要としないビジネスアプリケーションのクラウドサービスであれば、省電力型のカートリッジサーバによる仮想化を使わないベアメタルクラウド基盤が考えられます。しかし、ビッグデータ分析やHPC向けのクラウドサービスを提供するためには、比較的、性能の高いサーバを選択しなければなりません。
しかも、クラウドサービスとしての計算資源の提供となると、さまざまな種類のLinux OS環境とアプリケーション環境を素早く提供できなければなりません。場合によっては、複数のユーザーの負荷の高いワークロードが1つの物理サーバ上で同時に稼働する可能性もあります。そこで、最近になって注目を浴びているのがDockerを採用したベアメタルクラウド(物理クラウド)基盤です。Dockerは、ハイパーバイザー型の仮想化ソフトウェアに比べ、オーバーヘッドが非常に小さいことが特徴として挙げられます。そのため、性能劣化が許されないシステムへの活用が大きく注目されているのです。
ビッグデータ分析やHPCによる超高速処理のニーズに応えるベアメタルクラウドでは、Dockerを採用することで、オーバーヘッドによる性能劣化を回避しつつも、異なる種類のLinux OS環境をコンテナとして同時に稼働させることができます。Dockerでは、ユーザーが実際に利用するOS環境をコンテナとして複数稼働させることができ、配備、破棄が容易なため、クラウドサービスに非常に有用です。クラウド事業者にとって、ビッグデータ分析、人工知能、科学技術計算といった性能劣化が許されないサービスをクラウドとして提供できることは、ビジネスユース以外の新規顧客獲得のチャンスを広げます。
一方、Dockerによるベアメタルクラウドの利用者側にとってのメリットは、どのようなものでしょうか?例えば、科学技術計算を行うユーザーは、大学や研究所などにおいて、予算や使用期間の関係上、研究所や学内の共有の大型計算機を利用することが難しい場合があります。そのような場合、あらかじめクラウドを使用するための予算の確保が前提ですが、HPCアプリケーションや開発環境がすでに組み込まれたDockerイメージを使って、クラウド環境で素早く計算業務に取り掛かることができます。
また、クラウド上で稼働している自分のDockerコンテナをイメージとして手元にコピーすると、手元のDocker環境でコンテナとして再び稼働させることが可能となるため、ユーザーのアプリケーションの実行環境の可搬性を大きく高めます。これらのメリットは、ビッグデータ分析を行うユーザーにとっても同様です。

HPCアプリケーションの実行環境の可搬性を大きく高めるDocker
Dockerであっても、ビッグデータやHPCはハードウェア性能が非常に重要
Dockerは、複数のヘテロLinux OS環境をコンテナとして同時に稼働させることができ、しかも、オーバーヘッドも小さいため、ビッグデータやHPCのクラウドサービスを実現する技術要素として注目を浴びていますが、実際の導入にあたって注意すべき点があります。それは、ハードウェアの性能です。
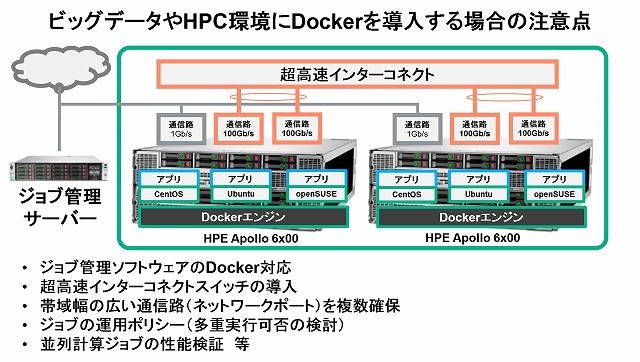
1つの物理サーバに複数ユーザーのアプリケーションが同時に稼働する場合、ユーザーにしかるべき計算資源が適切に割り当てられる必要があります。幸いなことに、Docker環境では、コンテナ毎にCPUコアやメモリ容量などを細かく指定することができますが、複数のユーザーが同時に利用する場合のアプリケーションの物理サーバへの配置、スケジューリングなども考慮する必要があります。
通常、スーパーコンピュータのシステムでは、1人のユーザーが膨大な物理サーバを占有することなく、複数のユーザーで計算資源を有効に利用するために、ジョブ投入やスケジューリングなどが行える「ジョブ管理ソフトウェア」が導入されています。このようなジョブ管理ソフトウェアをDocker環境でも利用できるように考慮する必要があります。
また、複数の物理サーバで並列計算を行うアプリケーションの場合は、サーバ同士の通信が頻繁に発生するため、非常に高性能なインターコネクトスイッチを導入し、広い帯域幅を持つ複数の通信路を確保しなければなりません。性能を引き出すためには、それなりにハードウェアに投資しなければなりませんが、ユーザーに計算資源が適切に割り当てられる仕組みと、複数ユーザーの同時利用に耐えられる物理基盤を用意しておかないと、Dockerによって高い柔軟性を得ることができたにもかかわらず、ユーザーが増えると計算速度が出ないという事態に陥るため、注意が必要です。
ビッグデータやHPC環境にDockerを導入する場合の注意点




