
では、Data Hubとは具体的にどのようなものなのか。McStravick氏は、誰がどのデータに何の目的でアクセスしたのか、データはどこからきてどこに向かうのか、などの「ガバナンス」、データを取り出して加工したり、他のデータと組み合わせるなどの「データパイプライン」、そしてデータをシステムを超えて共有する「共有」の3つの課題を解決するという。
ガバナンスでは、SAPソフトウェアに加えてHadoopやデータレークなどSAP以外のデータソースについて、データの利用や品質、などの情報を得られる。McStravick氏は、「企業が使うデータの半分以上が、自社以外のデータだ。Data Hubでは外部のデータソースから取り込む仕組みを提供する」と説明した。これにより、Hadoop、Spark、「SAP Vora」などの既存の投資を活用できるという。
パイプラインでは、グラフィカルなツールを利用してパイプラインの生成や変更が可能。Kubernetesを利用したコンテナオーケストレーションにより、カスタムコードも迅速に実行できるという。TensorFlowなどの機械学習ライブラリを活用することもでき、作成したパイプラインモデルの複製や再利用により迅速な展開を支援できる。
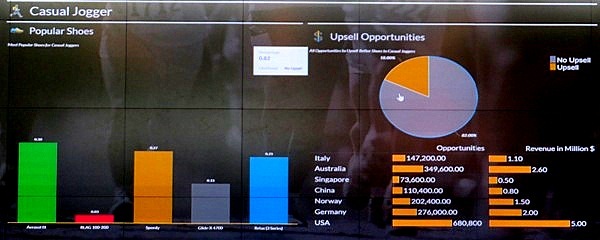
データから得られた洞察を視覚的に表示する。
最大の特徴は、データを動かさない点だ。「データを一箇所に中央化させるのではなく、データはある場所にそのままで、データの管理を中央化する」とMcStravick氏は強調する。
統合性も特徴で、Data Hubを開発したFranz Faerber氏は「Data Hubは技術やツールの集まりではなく、データサイロやデータシステムがあるデータ顧客のデータランドスケープに統合して、ガバナンス、パイプライン、データ統合を組み合わせた1つの一貫性のあるシステムだ」と説明した。
Data Hubはオンプレミス、クラウドで提供。同日一般提供を開始した。





