
SAPジャパンは11月7日、ビッグデータ活用基盤「SAP Data Hub」の提供を始めた。企業を取り巻くビッグデータ活用の課題解決を支援する。
ビッグデータの活用にはいくつかの課題が存在する。(1)そのビッグデータがいつどこで生成され、どのように加工されたのか、(2)生データを活用できるデータにするまでのプロセスに時間がかかる、(3)ビッグデータと基幹データの統合アクセスができない――といった問題が挙げられる。
Data Hubは、「データガバナンス」「データパイプライン」「データの共有」という3つの機能でこうした問題の解決を支援するものだ。SAP HANA、SAP BW、Amazon S3、Microsoft Azure、Apache Hadoopなど、オンプレミスやクラウドにある多種多様なデータレイクやデータウェアハウス、ストレージシステムに対応する。
データのクレンジングや成形、加工、集計といった一連のワークフローを“パイプライン”として定義する。GUIで視覚的に操作可能なため、ノンプログラミングでパイプラインを作成できる。TensorFlowなどの機械学習機能をパイプラインに組み込むことも可能。データ加工の傾向を分析し、その結果を加工処理パターンに反映させることができるという。
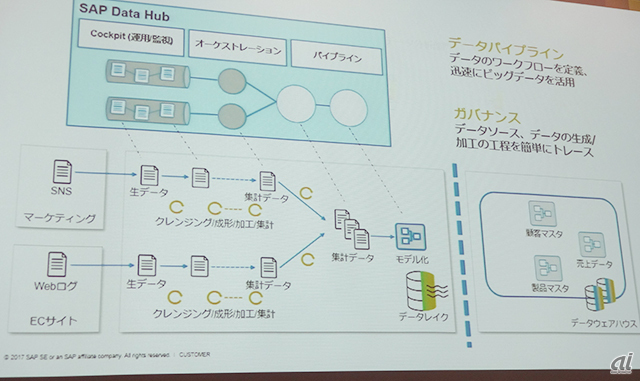
Data Hubの利用イメージ
Data Hubは、インメモリ分散処理エンジン「SAP Vora」上で稼働するため、Voraの分散インメモリ環境でパイプライン処理を高速に実行可能となっている。最新版の「SAP Vora 2.0」では、Google KubernetesとDockerコンテナに対応して動的なプロビジョニングとクラスタ管理が可能になったほか、Apche Spark 2.xやHadoop以外のデータストア技術をサポートしている。
管理画面では、データ処理のモニタリングやスケジューリング、データ環境全体の健全性を確認できる。自社データの利用状況や相互接続、品質管理をはじめ、メタデータモデルのリポジトリを構築することも可能。ソースからターゲットへのデータを保護するアクセスポリシーを動的に適用したり、機密情報を保護するためにデータをマスクして匿名化したりする機能も備える。
Data HubとHANAはシステムの親和性が高く、透過的なデータアクセスが可能だとしている。「ビッグデータと企業データの間にある溝をなくし、組織全体に広がったデータから価値を生み出すデータ駆動型アプリケーションをアジャイル開発できる」(SAPジャパン バイスプレジデント プラットフォーム事業本部長 鈴木正敏氏)
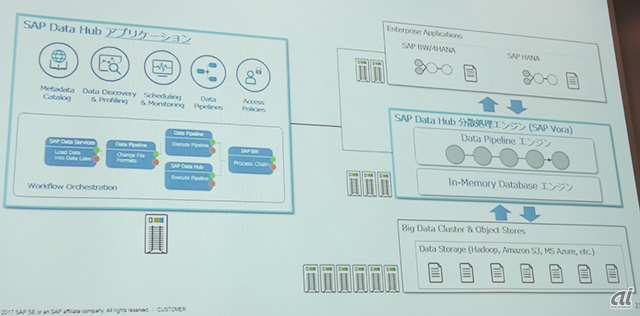
Data Hubのシステム構成




