
Facebookで使用しているサーバは1種類ではなく、本番環境の何百ものワークロードをいくつかに分類し、それぞれのタイプに合わせて専用サーバを設計している。データの保管には「Bryce Canyon」と「Lightning」を使用したストレージサーバを使用し、機械学習のトレーニングはNVIDIAの「Tesla」シリーズのGPUを搭載した「Big Basin」サーバで実行され、モデルの実行はシングルソケットの「Twin Lakes」またはデュアルソケットの「Tioga」のXeonプロセッサ搭載サーバで行われている。Hazelwood氏は、FacebookではGoogleの「TPU」やMicrosoftの「BrainWave FPGA」などの特化型のハードウェアも常に評価しているが、投資がコンピューティングに偏っており、ストレージや、特にネットワーキングに対する投資が十分でないため、多くのワークロードで「Amdahlの法則」についていけず、ボトルネックになってしまう可能性があると述べている。また、AI用プロセッサのスタートアップはこれまでソフトウェアスタックに十分に力を入れて来ておらず、機械学習ツールとコンパイラの分野に大きなチャンスが残っていると付け加えた。
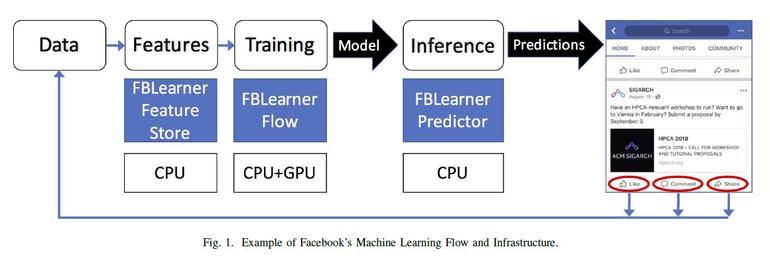
Facebook自身が開発しているソフトウェアスタックには、機械学習パイプラインの異なる部分に焦点を当てた、3つの管理・展開ツールから構成されている「FBLearner」が含まれている。「FBLearner Store」はデータの操作と特徴抽出を、「FBLearner Flow」はトレーニングに関する手順の管理を、「FBLearner Prediction」は本番環境でのモデルの展開をそれぞれ担っている。FBLearnerの目的は、生産性を向上させて、エンジニアがアルゴリズムの設計に取り組む時間の余裕を作ることだ。
Facebookは従来、2つの機械学習フレームワークを使用してきた。研究に適したPyTorch、本番対応に適した「Caffe」だ。PythonベースのPyTorchは扱いやすいが、パフォーマンスはCaffe2の方が高い。問題は、PyTorchからCaffe2の本番環境にモデルを移行する作業には時間が掛かり、ミスが起こることもあるということだ。この問題を受けて、Facebookは2018年5月に開発者カンファレンス「F8」で、「PyTorch 1.0」で「PyTorchの使い勝手とCaffe2のパフォーマンスを両立できるよう、この2つをマージした」と発表した。
これは、「ONNX」(Open Neural Network Exchange)に向けての最初の一歩としては合理的な対応だと言える。ONNXは、Facebook、Amazon、Microsoftが進めている、さまざまなハードウェアで、異なるフレームワークで構築された深層学習モデルを最適化して実行するためのオープンフォーマットを作る取り組みだ。問題は、Googleの「TensorFlow」、Microsoftの「Cognitive Toolkit」、Apacheの「MXNet」(Amazonが好んで利用している)などをはじめとして多くのフレームワークが存在しており、モデルを実行するプラットフォームも、「AppleML」、NVIDIA、Intelの「Nervana」、Qualcommの「Snapdragon Neural Processing Engine」など多岐に渡ることだろう。





