
日本IBMは10月9日、オンプレミス環境向けのデータ活用ソリューション「IBM Cloud Private for Data」を試用するためのホスティング型クラウドサービス「IBM Cloud Private Experiences」の提供を開始した。これに合わせて、データ活用の基盤となる「データカタログ」の整備を題材に記者説明会を開催した。
同社は9月上旬に開催した記者説明会で、今回の説明会の題材となる「データ活用基盤」の現状について紹介している。それによると、IBMのコグニティブコンピューティング技術「Watson」の企業導入プロジェクトにおいて、分析などにすぐ利用できるデータは3割以下にとどまる。

日本IBM 専務執行役員 IBMクラウド事業本部 副本部長兼第二営業統括担当の三瓶雅夫氏
今回の説明会で解説を行った専務執行役員 IBMクラウド事業本部 副本部長兼第二営業統括担当の三瓶雅夫氏もこの現状に触れ、「データカタログ」整備の必要性を提起した。その背景には、企業内のさまざまな事業部門あるいはITなどの管理部門が所管するデータでは、データ形式が統一されていない、データを保管するシステムの管理がバラバラ、システム間のデータの流れが把握されていない――といった複数の原因がある。
「私も最近まで現場に関与していたが、ある金融機関では支店ごとにデータ形式が異なり、ある流通企業では24時間と午前・午後というように形式が違うなど、データの整合性がボトルネックになっている状況を見てきた。一方で『デジタル変革に向けてデータを活用せよ』という命題があり、データ基盤を整備しなければ、活用に向かえないという課題が生じている」(三瓶氏)
今回の説明会で提唱した「データカタログ」は、企業内に散在する各種データの所在や整合性といった状況を可視化するとともに、人工知能(AI)や機械学習などの技術で使用するデータを容易に見つけ出したり、そうしたデータを目的の業務に利用できるものかといったコンプライアンス的な判断をしたりできるよう支援する基盤に当たる。
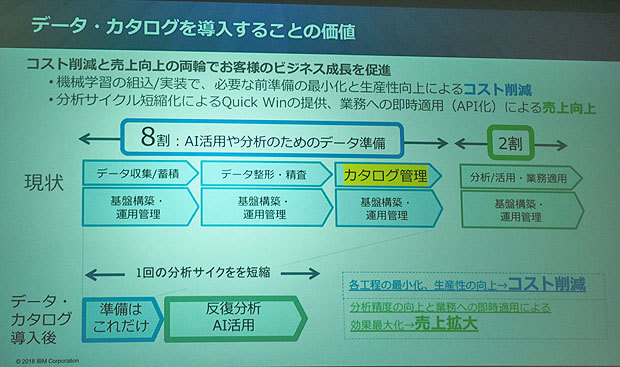
「データカタログ」を整備することにより、現在の作業の8割を占めるという「準備」の行程が大幅に省力化されるという
アナリティクス事業部 第二テクニカルセールス シニアITスペシャリストの高田和広氏は、IBM Cloud Private for Dataおよび同ソリューションの機能をマネージドサービスで提供する「IBM Watson Studio」で採用するデータカタログの機能を解説。その中では、例えば、事業部門のユーザーがビジネス用語(例えば「高付加価値顧客」)で分析に使いたいデータを検索し、そのデータの内容や管理者、所在を知ることができる。データにひも付く各種情報はメタデータとして管理され、ユーザーがこれを加工したり、用語辞書として部門をまたいで活用できるよう整理したりできるという。
また、データカタログではIT部門向けにデータの来歴管理機能を提供している。各種データがどのシステムに格納され、データが他のシステムに流れていく経路やETL処理の内容といった状況をグラフィカルユーザーインターフェース(GUI)で提示される。IT部門の管理者は、GUIによるドラッグ&ドロップ操作でこうしたデータ処理にまつわるプロセスを再定義するなど、データの適切な利用に向けた基盤整備を実施できるとしている。
こうしたETLやマスターデータ管理といった作業は、古くから企業データ管理にまつわる根本的な課題の解決に必要だとされてきた。それでも解決されないのは、データ活用の重要性が長らく認識されながらも、多種多様なデータの実態を可視化するためには膨大な時間と労力、部門間の垣根を越えた連携が必要となり、あまりにも大きな負担となることから敬遠されてきたためだ。
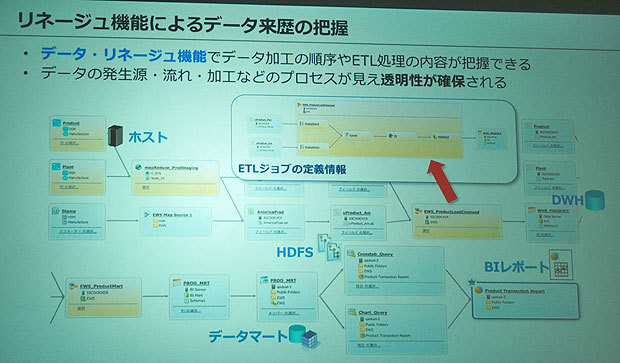
データの抽出、加工・変換、ロードのいわゆるETLは昔からデータ管理の重要な部分だが、デジタル変革の“文脈”で改めて重要性が提起されつつある
三瓶氏によれば、あらゆる企業がデジタル変革の取り組みを進めなければならない現実に直面しており、データ基盤の整備という“面倒”な取り組みにもはや背を向けることができなくなりつつある。このため、同社では「DataFirst Method」というリファレンスアーキテクチャをユーザーに提供しているといい、同氏は「まず事業部門やIT部門などの間を取り持ち、現状の棚卸しをして一丸で取り組んでいくための下地作りを行う。その支援を行っていきたい」と話している。




