人工知能(AI)プログラムのトレーニングに関する年2回のベンチマークテストで、GoogleとNVIDIAがトップの座を分け合ったことが、MLCommonsが米国時間6月29日に発表したデータで明らかになった。MLCommonsは、機械学習のパフォーマンス測定で人気のテスト「MLPerf」を統括する業界コンソーシアムだ。
提供:MLCommons
MLPerfのバージョン2.0ラウンドのトレーニング結果によると、市販されているシステム向けの4つのタスク、具体的には画像認識、物体検出(2種類)、およびBERT自然言語処理モデルで、Googleはニューラルネットワークのトレーニングにかかる時間が最も短く、最高スコアをマークした。
一方、NVIDIAは8つあるタスクのうち、残りの4つのタスクでトップに輝いている。こちらは画像セグメンテーション、音声認識、レコメンデーションシステム、および「MiniGo」データセットで碁を打つための強化学習だ。
両社とも複数のベンチマークテストで高いスコアを獲得したが、Googleが市販システム向けのテスト結果を報告したのは、トップスコアを獲得した4つのタスクのみで、他の4つのタスクについては報告していない。これに対して、NVIDIAはすべてのタスクのテスト結果を報告している。
このベンチマークテストは、ニューラルネットワークの「重み」、つまりパラメーターを調整して、コンピュータープログラムが所定のタスクで基準となる精度を達成するまでの時間を分単位で報告するものだ。この一連のプロセスは、ニューラルネットワークの「トレーニング」と呼ばれている。
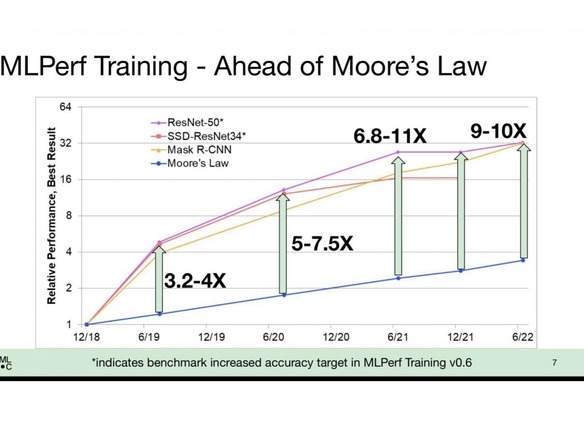
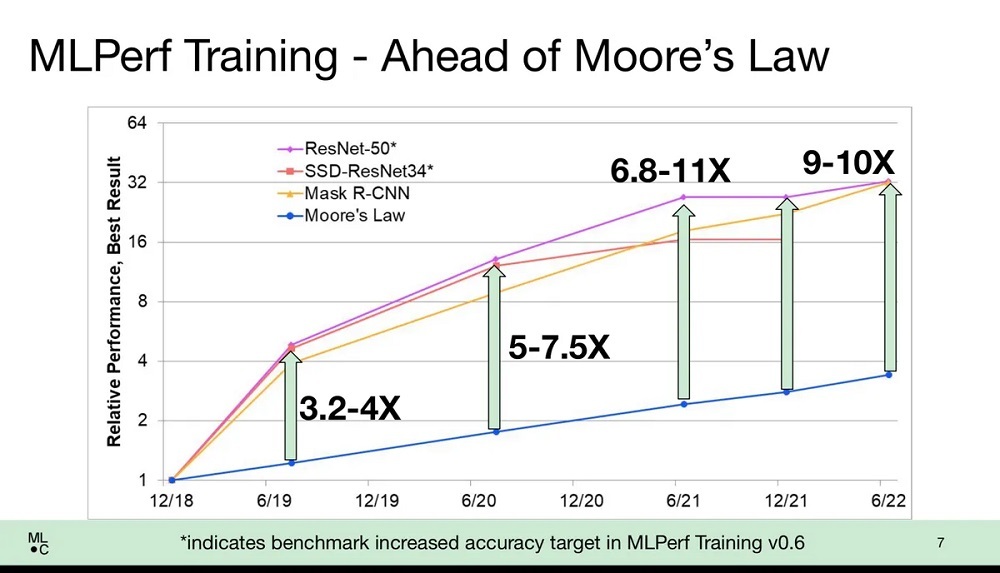
処理能力の向上とソフトウェアによるアプローチの高度化のおかげで、すべてのベンダーでトレーニング時間の大幅な短縮が認められた。MLCommonsのエグゼクティブディレクターを務めるDavid Kanter氏は、大まかに言えば、トレーニングに関してはムーアの法則を上回る勢いでパフォーマンスが向上していると、メディア向けの会見で説明した。ムーアの法則とは、チップに搭載可能なトランジスタの数が1年半ないし2年ごとに倍増し、それに伴ってコンピューターの性能が向上するというよく知られた経験則だ。
例えば、数百万件の画像に分類ラベルを割り当てるトレーニングをニューラルネットワークに対して行った場合、昔から使われてきたImageNetタスクのスコアは、チップの能力向上のみを考慮した場合よりもパフォーマンスの向上が著しく、9~10倍に達していると、Kanter氏は述べている。
「われわれはムーアの法則よりもはるかに優れた成果をあげている。トランジスタとパフォーマンスに直線的な関係があるとすれば、パフォーマンスの向上は3.5倍程度にとどまるはずだが、実際に得られている成果はムーアの法則の10倍の速度だ」と、Kanter氏は語った。
この性能向上の恩恵は搭載されているチップがわずか8つの「1台のワークステーションを使っている研究者」も含め、「ごく普通の人たち」にももたらされると、Kanter氏は述べた。
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。




