
東芝は3月13日、熟練者の知識を高度な保守業務に生かす「インフラ文書理解AI」を開発したと発表した。2024年にグループ内の事業現場で運用を開始し、将来的にはグループ内外の産業インフラ分野における予防保全にも適用するという。

東芝 研究開発センター 知能化システム研究所 アナリティクスAIラボラトリー エキスパートの井本和範氏
記者会見した研究開発センター 知能化システム研究所 アナリティクスAIラボラトリー エキスパートの井本和範氏は、「熟練者が少ない状況でも高品質な保守を実現し、予防保守による『攻めの保守』の実現を目指す。今後も継続的により高度な保守を実現するためにAI技術の開発を続け」と述べた。
同社が開発したのは、工場やプラントなどのインフラ分野で蓄積した機器の図面や仕様書、点検記録、トラブル記録などの専門的な文書を、高効率、高精度に認識して保守点検を支援する専門分野特化型の文書理解AIだ。
開発した技術の概要
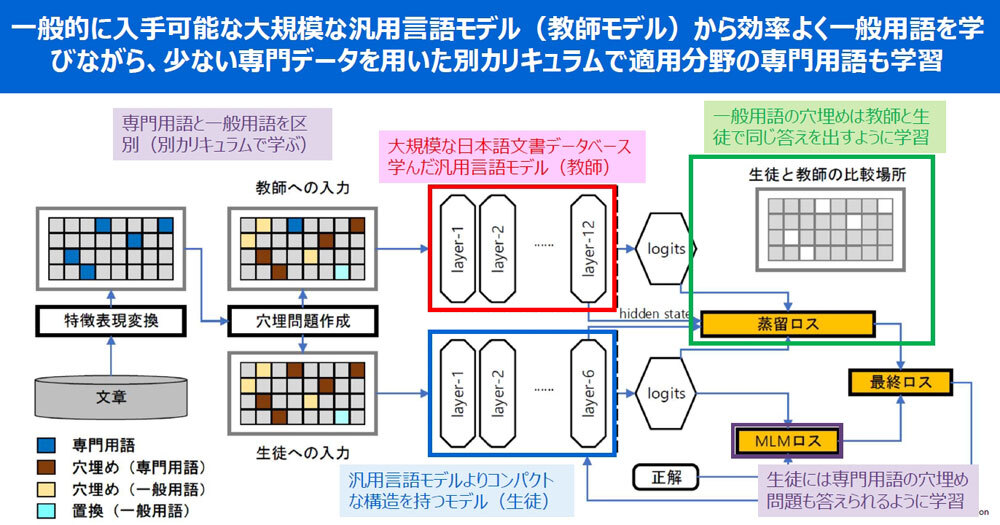
大規模な汎用言語モデルであるGoogleが提唱した「BERT」の日本語モデルを「教師」とし、文脈を正しく理解して、効率良く一般用語を学ぶ。具体的には、汎用言語モデルによって質疑応答に対応したり、日英語の機械翻訳を行ったり、人名や地名、イベントといった重要な情報をタグとして抽出するといったさまざまなタスクを実施する。
加えて東芝では、「生徒」となるAIモデルも開発。少ない専門データを用いた別のカリキュラムによって、適用分野の専門用語を学習する。モデルは、専門用語の穴埋め問題にも最適な回答が行えるようにする。
今回は、この2つのAIモデルを用いているのが特徴で、教師モデルと生徒モデルには、それぞれ複数の単語を隠した同じ専門データを入力。生徒モデルでは、隠された単語の一般用語部分については教師モデルと同じ答えを出力するように学習し、隠された単語の専門用語部分については正解と同じ答えを出力するように学習する。
この結果、一般用語と専門用語を同時に効率良く学習できる小規模な言語モデルを生成でき、少ない計算リソースで、高精度に専門的な文書を理解できるようになるという。
井本氏は、「AIをインフラ保守の現場に適用しようとしても、従来のAIは一般的な日本語には登場しないような事業分野ごとの専門用語はうまく扱えないなどの課題があった。それを解決するためには、個別事業分野への追加学習が必要で、多くの専門用語を含んだコーパスを用意する必要があったり、大規模汎用言語モデルの追加学習に多くの計算リソースを必要としたりする課題があった」と話す
だが、一般的に入手可能な大規模な汎用言語モデルとは別に、少ない専門データによって適用分野の専門用語を学習するモデルを別カリキュラムで動かすことにより、一般用語の知識を忘却することなく専門用語を追加できるという。





