
人工知能(AI)研究の世界では、ソフトウェアに関する技術的な詳細情報について、他の研究者がそのプログラムを理解し、そこから何かを学べるように、研究論文として公開するのが通例だ。

提供:Photo by Jakub Porzycki/NurPhoto via Getty Images
しかし、熱狂的な人気を博している対話型AI「ChatGPT」を手がけるOpenAIが、その心臓部を構成するプログラムの最新版「GPT-4」を米国時間3月14日にリリースしたとき、その伝統は絶たれた。
OpenAIのブログ投稿と併せて14日にリリースされたGPT-4の技術レポートでは、競争と安全性を考慮して技術的な詳細情報の提供を控えると述べている。
レポートには次のように書かれている。「GPT-4のような大規模モデルの競合状況および安全性の意味合いを考慮して」「このレポートでは(モデルサイズを含む)アーキテクチャー、ハードウェア、トレーニングコンピュート、データベースの構造、トレーニングメソッドなどの情報に関して、これ以上の詳細を述べない」
「アーキテクチャー」という用語は、人工ニューロンがどのように張り巡らされ、どのAIプログラムにも必要不可欠な要素がどのような状態であるかという、AIプログラムの基本的な構造を意味する。また、プログラムの「サイズ」とは、利用しているニューラルの「重み」、つまりパラメーターの数のことで、特定のプログラムが他のプログラムとの違いをだすための重要な要素の1つだ。
こうした詳細情報がないため、GPT-4は完全に謎のプログラムだ。この研究論文は、その意味で研究内容を何も明らかにしていない。
このプログラムの構造について、レポートでは2つの文で非常に大まかに説明している。
「GPT-4は、文書内の次のトークンを予測する訓練済みの『Transformer』形式モデルで、(インターネットデータなどの)利用可能な公開データと外部の提供事業者からライセンス供与されたデータの両方を利用している。モデルはその後、人間によるフィードバックを用いた強化学習(RLHF:Reinforcement Learning from Human Feedback)によって微調整されている」
どちらの文も、このプログラムをざっと見れば分かる程度のことしか述べていない。
こうした秘密主義は大半のAI研究者のやり方と異なる。他の研究所では詳細な技術的情報だけでなくソースコードも投稿することが多い。そうすることで他の研究者が結果を再現できるからだ。
さらに、情報を非公開にするのは、これまで情報を限定的に公開してきたOpenAIのやり方とも異なっている。
GPT-4は、その名称から分かるように、人間の言語を扱うために開発された「GPT」(Generative Pre-trained Transformer)というプログラムの4番目のバージョンだ。最初のバージョンを2018年にリリースした際、OpenAIはソースコードを公開しなかった。しかし同社は、GPT-1の各種パーツをどのように構成したか、つまりアーキテクチャーについて詳細に説明した。
そうした技術情報が公開されたため、多くの研究者は構造を再現することは無理だとしても、プログラムの機能に関して推論することはできた。
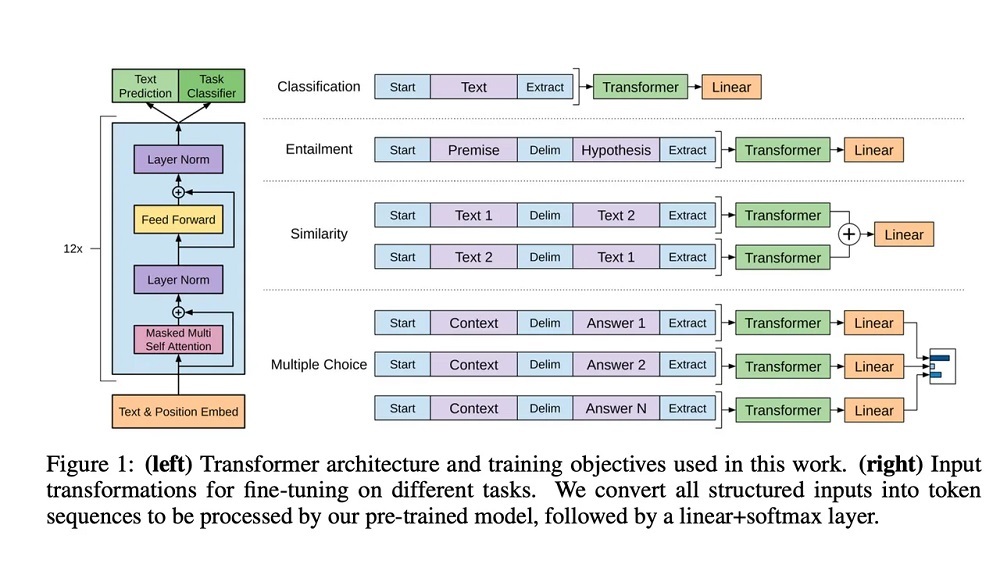
2018年に公開されたGPT-1の構造図。GPT-4はこうした詳細が明らかにされていない
提供:OpenAI
過去のやり方に反して、GPT-4の技術レポートは初めて非公開という方向に舵を切った。ソースコードや完成したプログラムだけでなく、外部の研究者がプログラムの構造を推測するための技術的な詳細情報も差し控えるという決定は、新たな種類の情報欠落と言えるだろう。
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。





