インテルは11月27日、人工知能(AI)の取り組みについて記者説明会を開催した。執行役員常務 技術本部 本部長の土岐英秋氏によると、グローバルでは2019年のAI関連の売上高が既に35億ドルに達するという。

インテル 執行役員常務 技術本部 本部長の土岐英秋氏
「インテルでは、推論性能に優れたCPUから、GPUやFPGA、そしてAI専用のASICに至るまで、あらゆる領域でAIを展開している。もちろん、全てにセキュリティ機能を組み込み、単独デバイスだけでなくエンドツーエンドでセキュリティを担保できるよう努めている」と土岐氏は述べている。
CPUについては、「AI Readyな設計になっている」と土岐氏。次世代のXeon Scalable Processorである「Cooper Lake」(開発コード名)では、「Deep Learning Boost」技術により30倍の推論性能を持ち、AIの計算効率化に有効なbfloatもサポートする。GPUは、単体製品を間もなく投入する予定だ。FPGAは、ハードウェアアクセラレーターとして活用することで高速化が可能なほか、「エッジ側でAI処理をする際は消費電力が限られるが、CPUやGPUと比較してFPGAは電力効率が高いため、エッジ側でも使われるようになるだろう」としている。
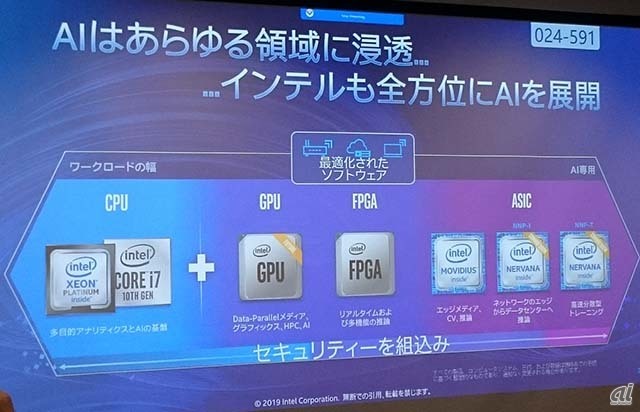
あらゆる領域でAIを展開するインテル
エッジAI戦略としては、ディープラーニングの推論処理を向上させる「OpenVINOツールキット」も用意している。通常、アーキテクチャーが異なると独立したソフトウェア環境を用意し、マニュアルでワークロードを振り分ける必要があるが、「OpenVINO環境であれば、1つの開発環境でさまざまなアーキテクチャーにどのワークロードを振り分けるか、ソースコード1本で管理できる」と土岐氏は説明する。
OpenVINOによるワークロードの振り分けをクラウド上でテストする「Dev Cloud」という環境も用意している。テスト開発したソースコードを、どの割合でCPUやGPUに振り分けるかといったコンフィグレーションをクラウド上でテストし確認できるという。
2020年前半には、エッジAI向けに設計された次世代の「Movidius Myriad Vision Processing Unit(VPU)」である「Keem Bay」(開発コード名)も登場する。オンチップメモリーを持つことでプロセッサーユニットの性能を効率的に活用でき、前世代と比較して約10倍の性能を実現するという。土岐氏は、Keem Bayと競合製品との差についても触れ、「NVIDIA TX2と比較するとパフォーマンスが約4倍、NVIDIA Xavierと比較すると5分の1のパワーで同等の性能が出る」とした。

Movidius VPU
また土岐氏は、11月中旬に初めてデモが披露されたばかりのディープラーニング用専用ASIC製品「インテル Nervana ニューラル・ネットワーク・プロセッサー(NNP)」についても説明した。Nervana NNPには、推論用の「NNP-I」と、学習用の「NNP-T」が用意されており、両製品ともに2019年中に生産を開始する。

Nervana NNP
NNP-Iは、手のひらサイズの大きさで、1秒に50兆回の計算が可能。電力効率に優れており、「提供開始時の市販アクセラレーターとしてはワット数当たりの性能が最高値になる見込み」(土岐氏)だという。Nervana NNP-Tは、モデルを効率的にトレーニングするよう、ほぼリニアにスケーリングができる。土岐氏は「ResNet 50とBERTにて最大95%の精度を出せる」としている。
さらに土岐氏は、インテルのXeアーキテクチャーをベースとしたHPCおよびAI向けのGPU「Ponte Vecchio」(開発コード名)についても触れた。これは、「データ並列ベクターマトリクスエンジンで、倍精度浮動小数点における高いスループットを実現、キャッシュとメモリーの帯域幅が大きいことが特徴だ」と土岐氏。プロセスノードは7nm、Compute Express Link(CXL)規格ベースのXeリンクを用意し、次世代の3Dパッケージング技術「Foveros」を採用する。提供時期などはまだ公表されていない。