
2020年12月15日、11月の米大統領選挙を受けて、選挙人による投票が全米各地で行われ、民主党のJoe Biden氏が当選に必要な過半数の270票以上を獲得し、次期大統領となる見通しとなった。しかし、現在もなお、不正な投票があったかどうかを巡る問題についての議論や訴訟が行われており、Donald Trump現大統領は、結局、敗北宣言を出さないという異例の選挙となった。今回の選挙で決着の一つの鍵となった要因として「郵便投票」の存在が挙げられる。実際、幾つかの接戦州では郵便投票の開票が進むにつれて、Biden氏がTrump氏を逆転するという現象が見られた。コロナ禍の環境において、集団感染を防ぐための「郵便投票」の存在は、民主主義の根幹である「投票権」を守る上で大いに役に立ったと思われるが、一方で、本人確認の難しさから「投票の真正性」の確保という点で課題を残したといえる。
ここでいう課題は、「本当に正しかったのか」ということだけでなく、「正しいことを証明・確認するための手間・コスト」も含んでいる。もし、郵便投票ではなく、例えば、スマートフォンやキオスク端末経由で安全・安心に投票が実施できたなら、人による数え間違いなどの問題が減り、大きなコスト削減も見込める。また、気軽に民意を問うことができるという点で、民主主義政治の在り方さえ変えるかもしれない。しかし、それは投票の信頼性確保の課題が、物理空間からサイバー空間に移転しただけだという見方もできる。電子投票の信頼性確保のためのセキュリティ対策や事故対応コストが膨大となってしまうのであれば、採用が難しくなってしまうだろう。
スマートシティーの「データ活用」を考える場合にも、その「信頼性」が全てのビジネスの根幹をなすことは言うまでもない。今回は、スマートシティーで活用するデータの信頼性を確保するため、データのリスクに応じた効率的なセキュリティ対策要件を検討するための考え方を示す。具体的には、前回紹介した総務省のガイドライン(PDF)や経済産業省の「サイバー・フィジカル・セキュリティ対策フレームワーク」(CPSF※)といったフレームワークレベルの議論を掘り下げて、個別のシステムのセキュリティ対策要件にたどり着くために必要な「データのモデル化」についての考え方を示す。
※Cyber/Physical Security Framework:経済産業省が2019年に公開した、Society 5.0を実現するためのセキュリティフレームワーク
CPSFにおけるデータ管理の考え方
スマートシティーのデータの信頼性について検討する前に、一般的なデータの信頼性の議論を紹介する。CPSFの実装を進めるために設立された「産業サイバーセキュリティ研究会:第3層セキュリティ対策検討タスクフォース(以下、第3層TF)」で検討されている「サイバー空間におけるデータの信頼性確保」(PDF)の考え方がその一例である。
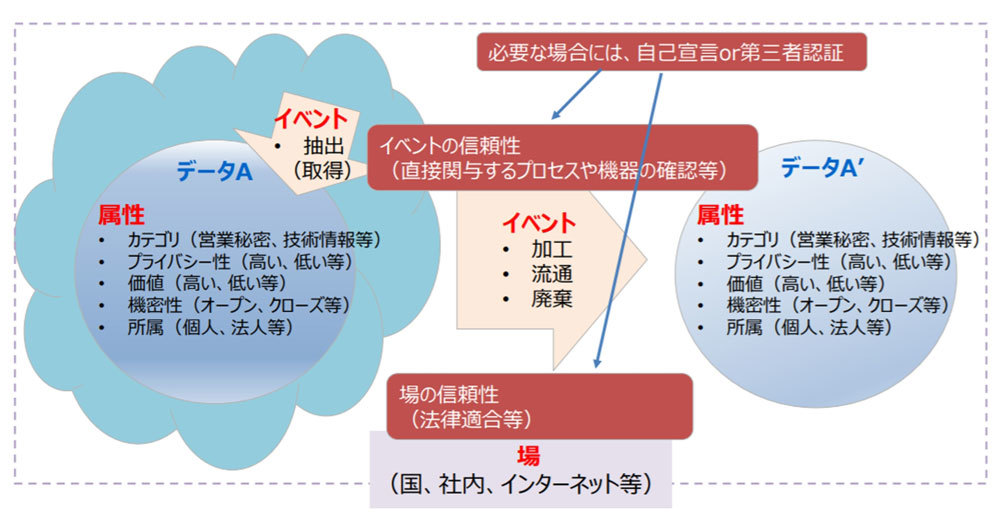
図1.データの信頼性の考え方(第3層TF資料より)
図1に、そのデータの信頼性確保の考え方について示した。データには、そのデータが有する性質である「属性」がある。どのようなタイプのデータか(カテゴリー)、プライバシー性はあるか(プライバシー性)、価値があるか(価値)、機密性があるか(機密性)、どこに所属しているか(所属)といったデータの重要性やリスクを判断するのに必要な情報がひもづいている。また、データの属性を生成・変化させる処理である「イベント」は、「収集」「流通」「加工」「廃棄」の4つである。
これらのイベントによってデータの状態が変化する。「収集」でデータが生まれ、「加工」「流通」を繰り返し、活用が終われば「廃棄」される。また、データの取り扱いは、特定の規範を共有する範囲である「場」にも左右される。例えば、国内でのみデータが流通するなら日本の法(個人情報保護法など)に従う。社内限りならば、社内ポリシーに従うだろう。同じ属性を持つデータであっても、場によって取り扱いが変わることがある。そして、データの信頼性は、この「イベント」と「場」の信頼性を確保することで得らえると考えるのである。
では、データが、適切なイベントによって生成され、場(法律・社内ポリシー)に適合している状態を実現するための具体的なセキュリティ対策要件とは、どのように定めれば良いのだろうか。第3層TFでは、データの重要性に応じてセキュリティ対策のレベルを分けることを提示している(図2)。このセキュリティレベルとセキュリティ対策要件の対応付けを定義できたとすれば、データのセキュリティレベルを決めることで、そのセキュリティ対策要件が明確になるため、データの有効活用がしやすくなることが期待できる。
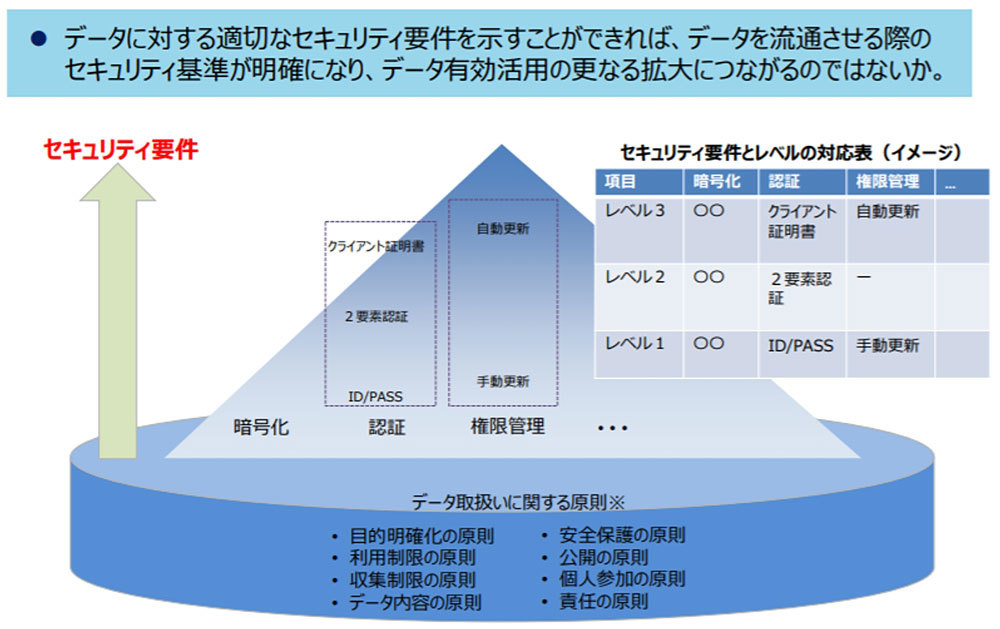
図2.データに対するセキュリティ要件とレベルの対応イメージ(第3層TF資料より)





