~「AWS LLM開発支援プログラム」で開発、近日公開予定~
カスタマーサポートDXを推進するカラクリ株式会社(東京都中央区:代表取締役CEO 小田志門、以下カラクリ)は、アマゾン ウェブ サービス ジャパン合同会社(以下、AWSジャパン)の「AWS LLM 開発支援プログラム」を活用し、2023年9月より国内最大規模となる700億パラメーターのLLMを開発いたしました。2024年1月18日に、LLMのベンチマークテスト「Japanese MT-Bench」で性能評価を実施し、国産LLMモデルとして最高性能(※)の評価が採点されました。世界市場での競争力を持った国産AIモデルの構築を加速するため、本モデルを公開可能な形に修正して、近日中に公開する予定です。
[画像1: (リンク ») ]
[画像2: (リンク ») ]
※ 「Japanese MT-Bench」はStability AI社が提供しているベンチマークテストです。2024年1月18日に性能評価した結果、国産モデルとして最高点の評価を得ました。ベンチマークテストとは、定められた基準を元にその性能を測定する方法で、「Japanese MT-Bench」はGPT-4を評価者としたものです。1~3位はOpenAI社開発、4~6位はアメリカのAnthropic社、7位・8位フランスのMistralAI社開発、9位はGoogle社開発、10位はイギリスのStability AI海外ベンチャー開発のLLMモデルです。
最高性能を評価された国産LLMについて
カラクリは「カスタマーサポートをエンパワーメントする」をブランドパーパスに掲げ、大規模言語モデル(LLM)のカスタマーサポートへの実用化を目指しております。そのため、日本語に強く、カスタマーサポート業務に特化したLLM開発に注力している中で、2023年9月に「AWS LLM 開発支援プログラム」に採択いただき、700億パラメーターの開発に着手いたしました。AWSの機械学習トレーニング用のアクセラレーターであるAWS Trainiumを活用し、開発から4ヵ月を経て、国産モデルLLMとして最高性能を獲得いたしました。今後、更なる改良を重ねカスタマーサポート特化型LLMへと精度を高めてまいります。
【独自データの収集】
日本語に強くカスタマーサポート業務に最適な国産LLMを開発するため、公開データセットに加えて3つの独自データを収集しております。
(1)カスタマーサポートに特化したデータ
カラクリ独自のプログラムで、インターネット上で公開されているデータの中からカスタマーサポート業務に特化したデータのみを抽出し、170億字分の学習データを確保いたしました。
(2)カラクリ作成データ
カラクリは2018年よりカスタマーサポート業務に特化したAIチャットボットを大手企業に向けて提供してまいりました。本ツールの提供を通じて培ったノウハウを活かし、社内のスペシャリストの手によってカスタマーサポートで想定される多種多様な業務に関する指示と応答の高品質なテキストデータを作成いたしました。
(3)カラクリ保有データ
カラクリが保有し、個人情報等を含まない利用者の許諾を得たデータを活用いたしました。
【学習方法】
本モデルは「Llama2」をベースとした事前学習を行っており、上記のカラクリ独自データを用いてファインチューニングを行っております。詳しくは当社Techブログに公開予定です。よろしければフォローください。
(リンク »)
【今後の展望】
今回、国産モデルの中でも最高性能という結果がでましたが、カスタマーサポート業務支援のプロダクト活用を実現するには、課題はまだ多く存在しています。それらをクリアし、カスタマーサポートのDXを促進するリーディングカンパニーとしての役割を担ってまいります。
カラクリ株式会社 CPO 中山智文コメント
[画像3: (リンク ») ]
LLMの開発に関する投資をするべきかどうか、初めは非常に迷いました。しかし、カラクリが挑戦しなければ、カスタマーサポート業界におけるAI活用は一体誰が担うのかと思い至り、このプロジェクトを実施する決意をしました。
現在はまだ途中経過の報告段階ではありますが、国産モデル最高性能という優れた成果を残すことができたことを大変嬉しく思います。AWS様をはじめとするご支援いただいた皆様、リソースが限られる中で創意工夫を凝らしたR&Dチームのメンバーたち、この投資にご理解を示してくださった社内外のステークホルダーの皆様がいなければ、この成果は得られませんでした。大変感謝しております。また、この成果は私たちだけの努力だけでなく、多くの先行研究やオープンソースソフトウェアの活用によるものです。巨人の肩の上に立っていることを忘れず、今後も人類の発展に貢献していきたいと考えています。
LLM開発に関するこれまでの取り組み
カラクリは2018年にTransformerを用いた言語モデルBERTの研究を開始し、その後もGPTを含めたLLMの研究に従事してまいりました。大規模言語モデルの社会実装における課題(膨大な運用コスト、セキュリティの課題、誤った情報の流布など)をクリアにしていくため、カラクリは創業当時より蓄積してきたカスタマーサポート業務に関わる高品質な学習データとノウハウを活かし、特有のニーズに適したAIソリューションの提供を目指します。また日本国内の産業や社会への貢献のみならず、世界市場での競争力を持った国産AIモデルの構築を視野に入れ、LLMの社会実装を加速します。
[表: (リンク ») ]
生成AIを搭載したサービス・プロジェクト
大手企業向け高精度AIチャットボット「KARAKURI chatbot」
(リンク »)
メール・チャットのオペレーター支援ツール「KARAKURI assist」
(リンク »)
Azure OpenAI Service東日本リージョン対応「KARAKURI AI playground」
(リンク »)
企業ごとにカスタマイズできる大規模言語モデル構築サービス「Custom LLM」
(リンク »)
明治安田生命保険相互会社と実施した「FAQ自動生成プロジェクト」
(リンク »)
AWS LLM開発支援プログラム
AWSジャパンが日本独自の施策としてLLM 開発を行う日本法人または拠点を持つ企業・団体を支援するプログラムです。本プログラムでは、LLM 開発を行うための計算機リソース確保に関するガイダンス、AWS 上での LLM 事前学習に関わる技術的なメンタリング、LLM 事前学習用クレジット 及びビジネス支援等のサポートが提供されます。
詳細: (リンク »)
会社概要
[画像4: (リンク ») ]
カラクリは「カスタマーサポートをエンパワーメントする」をブランドパーパスに掲げ、大規模言語モデル(LLM)のカスタマーサポートへの実用化を目指した事業を展開しています。2018 年より transformer を用いた言語モデルBERT を、2022 年からは GPT を含めた大規模言語モデルの研究を実施。主力ビジネスである高精度 AI チャットボット「KARAKURI chatbot」は、高島屋、SBI 証券、セブン-イレブン・ジャパン、SmartHR など各業界のトップランナーに選ばれつづけています。2018 年の ICC サミット「スタートアップ・カタパルト」に入賞、2020 年に「Google for Startups Accelerator」に採択、2023 年に「AWS LLM 開発支援プログラム」に採択されました。
住所 : 〒104-0045 東京都中央区築地2-7-3 Camel 築地 II
設立 : 2016年10月3日
代表者 : 代表取締役CEO 小田 志門
事業内容 : カスタマーサポート特化型AI「KARAKURI」シリーズの開発・提供・運営など
URL : (リンク »)
プレスリリース提供:PR TIMES (リンク »)
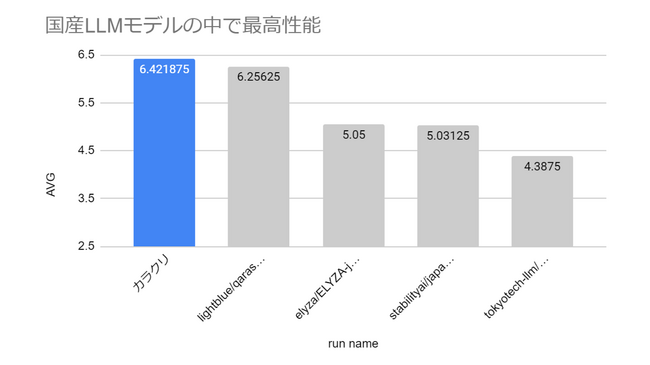
カスタマーサポートDXを推進するカラクリ株式会社(東京都中央区:代表取締役CEO 小田志門、以下カラクリ)は、アマゾン ウェブ サービス ジャパン合同会社(以下、AWSジャパン)の「AWS LLM 開発支援プログラム」を活用し、2023年9月より国内最大規模となる700億パラメーターのLLMを開発いたしました。2024年1月18日に、LLMのベンチマークテスト「Japanese MT-Bench」で性能評価を実施し、国産LLMモデルとして最高性能(※)の評価が採点されました。世界市場での競争力を持った国産AIモデルの構築を加速するため、本モデルを公開可能な形に修正して、近日中に公開する予定です。
[画像1: (リンク ») ]
[画像2: (リンク ») ]
※ 「Japanese MT-Bench」はStability AI社が提供しているベンチマークテストです。2024年1月18日に性能評価した結果、国産モデルとして最高点の評価を得ました。ベンチマークテストとは、定められた基準を元にその性能を測定する方法で、「Japanese MT-Bench」はGPT-4を評価者としたものです。1~3位はOpenAI社開発、4~6位はアメリカのAnthropic社、7位・8位フランスのMistralAI社開発、9位はGoogle社開発、10位はイギリスのStability AI海外ベンチャー開発のLLMモデルです。
最高性能を評価された国産LLMについて
カラクリは「カスタマーサポートをエンパワーメントする」をブランドパーパスに掲げ、大規模言語モデル(LLM)のカスタマーサポートへの実用化を目指しております。そのため、日本語に強く、カスタマーサポート業務に特化したLLM開発に注力している中で、2023年9月に「AWS LLM 開発支援プログラム」に採択いただき、700億パラメーターの開発に着手いたしました。AWSの機械学習トレーニング用のアクセラレーターであるAWS Trainiumを活用し、開発から4ヵ月を経て、国産モデルLLMとして最高性能を獲得いたしました。今後、更なる改良を重ねカスタマーサポート特化型LLMへと精度を高めてまいります。
【独自データの収集】
日本語に強くカスタマーサポート業務に最適な国産LLMを開発するため、公開データセットに加えて3つの独自データを収集しております。
(1)カスタマーサポートに特化したデータ
カラクリ独自のプログラムで、インターネット上で公開されているデータの中からカスタマーサポート業務に特化したデータのみを抽出し、170億字分の学習データを確保いたしました。
(2)カラクリ作成データ
カラクリは2018年よりカスタマーサポート業務に特化したAIチャットボットを大手企業に向けて提供してまいりました。本ツールの提供を通じて培ったノウハウを活かし、社内のスペシャリストの手によってカスタマーサポートで想定される多種多様な業務に関する指示と応答の高品質なテキストデータを作成いたしました。
(3)カラクリ保有データ
カラクリが保有し、個人情報等を含まない利用者の許諾を得たデータを活用いたしました。
【学習方法】
本モデルは「Llama2」をベースとした事前学習を行っており、上記のカラクリ独自データを用いてファインチューニングを行っております。詳しくは当社Techブログに公開予定です。よろしければフォローください。
(リンク »)
【今後の展望】
今回、国産モデルの中でも最高性能という結果がでましたが、カスタマーサポート業務支援のプロダクト活用を実現するには、課題はまだ多く存在しています。それらをクリアし、カスタマーサポートのDXを促進するリーディングカンパニーとしての役割を担ってまいります。
カラクリ株式会社 CPO 中山智文コメント
[画像3: (リンク ») ]
LLMの開発に関する投資をするべきかどうか、初めは非常に迷いました。しかし、カラクリが挑戦しなければ、カスタマーサポート業界におけるAI活用は一体誰が担うのかと思い至り、このプロジェクトを実施する決意をしました。
現在はまだ途中経過の報告段階ではありますが、国産モデル最高性能という優れた成果を残すことができたことを大変嬉しく思います。AWS様をはじめとするご支援いただいた皆様、リソースが限られる中で創意工夫を凝らしたR&Dチームのメンバーたち、この投資にご理解を示してくださった社内外のステークホルダーの皆様がいなければ、この成果は得られませんでした。大変感謝しております。また、この成果は私たちだけの努力だけでなく、多くの先行研究やオープンソースソフトウェアの活用によるものです。巨人の肩の上に立っていることを忘れず、今後も人類の発展に貢献していきたいと考えています。
LLM開発に関するこれまでの取り組み
カラクリは2018年にTransformerを用いた言語モデルBERTの研究を開始し、その後もGPTを含めたLLMの研究に従事してまいりました。大規模言語モデルの社会実装における課題(膨大な運用コスト、セキュリティの課題、誤った情報の流布など)をクリアにしていくため、カラクリは創業当時より蓄積してきたカスタマーサポート業務に関わる高品質な学習データとノウハウを活かし、特有のニーズに適したAIソリューションの提供を目指します。また日本国内の産業や社会への貢献のみならず、世界市場での競争力を持った国産AIモデルの構築を視野に入れ、LLMの社会実装を加速します。
[表: (リンク ») ]
生成AIを搭載したサービス・プロジェクト
大手企業向け高精度AIチャットボット「KARAKURI chatbot」
(リンク »)
メール・チャットのオペレーター支援ツール「KARAKURI assist」
(リンク »)
Azure OpenAI Service東日本リージョン対応「KARAKURI AI playground」
(リンク »)
企業ごとにカスタマイズできる大規模言語モデル構築サービス「Custom LLM」
(リンク »)
明治安田生命保険相互会社と実施した「FAQ自動生成プロジェクト」
(リンク »)
AWS LLM開発支援プログラム
AWSジャパンが日本独自の施策としてLLM 開発を行う日本法人または拠点を持つ企業・団体を支援するプログラムです。本プログラムでは、LLM 開発を行うための計算機リソース確保に関するガイダンス、AWS 上での LLM 事前学習に関わる技術的なメンタリング、LLM 事前学習用クレジット 及びビジネス支援等のサポートが提供されます。
詳細: (リンク »)
会社概要
[画像4: (リンク ») ]
カラクリは「カスタマーサポートをエンパワーメントする」をブランドパーパスに掲げ、大規模言語モデル(LLM)のカスタマーサポートへの実用化を目指した事業を展開しています。2018 年より transformer を用いた言語モデルBERT を、2022 年からは GPT を含めた大規模言語モデルの研究を実施。主力ビジネスである高精度 AI チャットボット「KARAKURI chatbot」は、高島屋、SBI 証券、セブン-イレブン・ジャパン、SmartHR など各業界のトップランナーに選ばれつづけています。2018 年の ICC サミット「スタートアップ・カタパルト」に入賞、2020 年に「Google for Startups Accelerator」に採択、2023 年に「AWS LLM 開発支援プログラム」に採択されました。
住所 : 〒104-0045 東京都中央区築地2-7-3 Camel 築地 II
設立 : 2016年10月3日
代表者 : 代表取締役CEO 小田 志門
事業内容 : カスタマーサポート特化型AI「KARAKURI」シリーズの開発・提供・運営など
URL : (リンク »)
プレスリリース提供:PR TIMES (リンク »)
本プレスリリースは発表元企業よりご投稿いただいた情報を掲載しております。
お問い合わせにつきましては発表元企業までお願いいたします。
お問い合わせにつきましては発表元企業までお願いいたします。

