2017年11月1日
国立研究開発法人情報通信研究機構(NICT) (リンク »)
映像を見て感じた内容を脳から言葉で読み解く脳情報デコーディング技術を開発
~名詞・動詞だけでなく“印象”を形容詞の形で解読に成功~
【ポイント】
■ CMなどの映像を見て感じたことを、1万語の「名詞・動詞・形容詞」の形で脳活動から解読
■ より多種の物体・動作内容を読み解く技術に加え、新たに“印象”を読み出す技術を確立
■ テレビCMなどの映像コンテンツ評価や発話を介さないコミュニケーション技術への応用が可能
国立研究開発法人情報通信研究機構(NICT、理事長: 徳田 英幸)脳情報通信融合研究センター(CiNet)のグループは、映像を見て感じた「物体・動作・印象」の内容を、脳活動を読み解くことで、1万語の「名詞・動詞・形容詞」の形で言語化する脳情報デコーディング技術の開発に成功しました。従来の脳情報デコーディング技術では約500単語に対応する物体や動作の内容を解読していたのに比べ、本技術の開発により、おおよそ20倍の1万単語に対応する内容を脳から解読することが可能となりました。さらに、従来技術では解読できなかった“印象”の内容についても、形容詞の形で解読に成功しました。
本技術を基盤技術とすることで、映像を見て感じたことを脳活動から読み取り評価する脳情報デコーディング技術に基づく映像コンテンツ評価手法や、発話や筆談が困難な方々などが頭の中で考えただけで内容を言語化してコミュニケーションを行う手段などの社会実装が期待されます。映像コンテンツ評価手法については、2016年度から開始したCMなどの映像コンテンツ評価サービス事業に本技術が利用されています。
なお、この成果は、神経科学の国際科学誌「NeuroImage (リンク ») 」オンライン版に掲載されました。
【背景】
画像や映像を見て感じたことを脳活動から読み取る脳情報デコーディング技術は、脳と機械のインタフェースなどの未来の情報通信技術の基盤技術として重要な役割を担う技術です。近年、その一つの実装の形として、感じたことを単語の形で言語化して脳活動から読み取る技術が開発されています。これまでには、映像を見て感じた物体と動作の内容を、約500語の単語の形で推定した例があります。しかし、500単語といえども、実世界において私たちが感じる多様な内容のごく一部を反映するに過ぎません。また、映像を見て感じる内容としても、物体と動作のほかにも印象のような異なる種類の内容も存在します。脳情報デコーディング技術を社会で実用化するためには、もっと多様な内容をもっと多くの単語に対応する形で脳活動から読み取ることが必要となります。
【今回の成果】
本研究において、CiNetの西田知史研究員と西本伸志主任研究員は、映像を見て感じる様々な「物体・動作・印象」の内容を、それらに対応する1万語の「名詞・動詞・形容詞」の形で推定する脳情報デコーディング技術を開発しました。
この技術の特徴は、大規模テキストデータから学習した言語特徴空間を、脳活動の解読装置であるデコーダーに取り入れて、映像を見て感じた内容の推定に利用した点です。ここでの言語特徴空間とは、単語同士の意味的な近さ・遠さを空間内の位置関係により表現する100次元空間のことです。この空間内では、大規模テキストデータに含まれている1万語の「名詞・動詞・形容詞」がそれぞれ空間内の1点として表現されており、意味の近い単語(例: 猫と犬)は近い距離で表現され、意味の遠い単語(例: 猫と建物)は遠い距離で表現されます。この1万語の表現を持つ言語特徴空間を取り入れることによって、従来技術の約20倍となる1万単語を用いて、脳活動から映像を見て感じたことの解読が可能となりました。
さらに、従来技術では名詞・動詞に対応する物体・動作の内容のみを解読していましたが、言語特徴空間に含まれる形容詞を用いて、対応する“印象”内容も感じた内容として解読することに初めて成功しました。
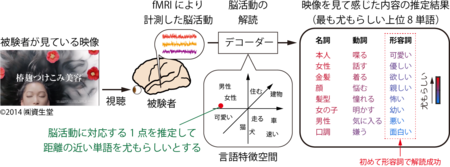
本技術を使用し、映像を見て感じた内容の解読を行った一例を図1に示します。
本技術は、CMなどの自然な映像を視聴中の被験者から機能的磁気共鳴画像法(fMRI)により計測した脳活動を、解読の対象とします。脳活動の解読を行うデコーダーは、脳活動と言語特徴空間の対応関係を保持しており、新しい脳活動が入力されると、対応関係を利用して言語特徴空間内の1点を推定します。そして、脳活動から推定した点からの距離の近さに基づいて、1万単語それぞれのもっともらしさを出力します。もっともらしい単語ほど、その被験者が映像を見て感じた内容に近いとみなします。図1右の単語リストが、図1左の映像を視聴中の脳活動から実際に推定した、もっともらしさの高い最上位単語を、名詞(物体)・動詞(動作)・形容詞(印象)に分けて出力した結果になります。
本技術は、自然な映像から感じた様々な物体・動作・印象の内容を、1万語の単語として解釈しやすい形で解読できることから、脳情報デコーディング技術の実社会における実用化を促進する技術だといえます。
【今後の展望】
今後は、映像から感じた内容の推定精度の向上を目指すとともに、推定された内容がどのように個性や購買行動と結び付くのかといった点についても検証を行う予定です。
また、発話や筆談が困難な方々などが利用可能な発話を介しない言語化コミュニケーション技術に対しても、さらに、その応用技術の幅広い社会実装を、産学官の連携で目指していきます。
なお、本技術は、NICTから株式会社NTTデータにライセンス提供され、「脳情報デコーディング技術に基づいたCMなどの映像コンテンツ評価サービス(NeM sweets DONUTs)」として、2016年度から株式会社NTTデータにより事業展開されています。
国立研究開発法人情報通信研究機構(NICT) (リンク »)
映像を見て感じた内容を脳から言葉で読み解く脳情報デコーディング技術を開発
~名詞・動詞だけでなく“印象”を形容詞の形で解読に成功~
【ポイント】
■ CMなどの映像を見て感じたことを、1万語の「名詞・動詞・形容詞」の形で脳活動から解読
■ より多種の物体・動作内容を読み解く技術に加え、新たに“印象”を読み出す技術を確立
■ テレビCMなどの映像コンテンツ評価や発話を介さないコミュニケーション技術への応用が可能
国立研究開発法人情報通信研究機構(NICT、理事長: 徳田 英幸)脳情報通信融合研究センター(CiNet)のグループは、映像を見て感じた「物体・動作・印象」の内容を、脳活動を読み解くことで、1万語の「名詞・動詞・形容詞」の形で言語化する脳情報デコーディング技術の開発に成功しました。従来の脳情報デコーディング技術では約500単語に対応する物体や動作の内容を解読していたのに比べ、本技術の開発により、おおよそ20倍の1万単語に対応する内容を脳から解読することが可能となりました。さらに、従来技術では解読できなかった“印象”の内容についても、形容詞の形で解読に成功しました。
本技術を基盤技術とすることで、映像を見て感じたことを脳活動から読み取り評価する脳情報デコーディング技術に基づく映像コンテンツ評価手法や、発話や筆談が困難な方々などが頭の中で考えただけで内容を言語化してコミュニケーションを行う手段などの社会実装が期待されます。映像コンテンツ評価手法については、2016年度から開始したCMなどの映像コンテンツ評価サービス事業に本技術が利用されています。
なお、この成果は、神経科学の国際科学誌「NeuroImage (リンク ») 」オンライン版に掲載されました。
【背景】
画像や映像を見て感じたことを脳活動から読み取る脳情報デコーディング技術は、脳と機械のインタフェースなどの未来の情報通信技術の基盤技術として重要な役割を担う技術です。近年、その一つの実装の形として、感じたことを単語の形で言語化して脳活動から読み取る技術が開発されています。これまでには、映像を見て感じた物体と動作の内容を、約500語の単語の形で推定した例があります。しかし、500単語といえども、実世界において私たちが感じる多様な内容のごく一部を反映するに過ぎません。また、映像を見て感じる内容としても、物体と動作のほかにも印象のような異なる種類の内容も存在します。脳情報デコーディング技術を社会で実用化するためには、もっと多様な内容をもっと多くの単語に対応する形で脳活動から読み取ることが必要となります。
【今回の成果】
本研究において、CiNetの西田知史研究員と西本伸志主任研究員は、映像を見て感じる様々な「物体・動作・印象」の内容を、それらに対応する1万語の「名詞・動詞・形容詞」の形で推定する脳情報デコーディング技術を開発しました。
この技術の特徴は、大規模テキストデータから学習した言語特徴空間を、脳活動の解読装置であるデコーダーに取り入れて、映像を見て感じた内容の推定に利用した点です。ここでの言語特徴空間とは、単語同士の意味的な近さ・遠さを空間内の位置関係により表現する100次元空間のことです。この空間内では、大規模テキストデータに含まれている1万語の「名詞・動詞・形容詞」がそれぞれ空間内の1点として表現されており、意味の近い単語(例: 猫と犬)は近い距離で表現され、意味の遠い単語(例: 猫と建物)は遠い距離で表現されます。この1万語の表現を持つ言語特徴空間を取り入れることによって、従来技術の約20倍となる1万単語を用いて、脳活動から映像を見て感じたことの解読が可能となりました。
さらに、従来技術では名詞・動詞に対応する物体・動作の内容のみを解読していましたが、言語特徴空間に含まれる形容詞を用いて、対応する“印象”内容も感じた内容として解読することに初めて成功しました。
本技術を使用し、映像を見て感じた内容の解読を行った一例を図1に示します。
本技術は、CMなどの自然な映像を視聴中の被験者から機能的磁気共鳴画像法(fMRI)により計測した脳活動を、解読の対象とします。脳活動の解読を行うデコーダーは、脳活動と言語特徴空間の対応関係を保持しており、新しい脳活動が入力されると、対応関係を利用して言語特徴空間内の1点を推定します。そして、脳活動から推定した点からの距離の近さに基づいて、1万単語それぞれのもっともらしさを出力します。もっともらしい単語ほど、その被験者が映像を見て感じた内容に近いとみなします。図1右の単語リストが、図1左の映像を視聴中の脳活動から実際に推定した、もっともらしさの高い最上位単語を、名詞(物体)・動詞(動作)・形容詞(印象)に分けて出力した結果になります。
本技術は、自然な映像から感じた様々な物体・動作・印象の内容を、1万語の単語として解釈しやすい形で解読できることから、脳情報デコーディング技術の実社会における実用化を促進する技術だといえます。
【今後の展望】
今後は、映像から感じた内容の推定精度の向上を目指すとともに、推定された内容がどのように個性や購買行動と結び付くのかといった点についても検証を行う予定です。
また、発話や筆談が困難な方々などが利用可能な発話を介しない言語化コミュニケーション技術に対しても、さらに、その応用技術の幅広い社会実装を、産学官の連携で目指していきます。
なお、本技術は、NICTから株式会社NTTデータにライセンス提供され、「脳情報デコーディング技術に基づいたCMなどの映像コンテンツ評価サービス(NeM sweets DONUTs)」として、2016年度から株式会社NTTデータにより事業展開されています。
本プレスリリースは発表元企業よりご投稿いただいた情報を掲載しております。
お問い合わせにつきましては発表元企業までお願いいたします。
お問い合わせにつきましては発表元企業までお願いいたします。

