バッチ処理を分散・並列実行して高速化
大量データを分散・並列実行してバッチ処理を高速化し、ITコストの適正化や、基幹系システム向けにも対応する高い可用性を実現するのが日立の「グリッドバッチソリューション(以下、グリッドバッチ)」だ。
単一ハードで実現する従来の一般的な処理システムでは、処理性能の限界がCPUやI/O速度に依存しやすく、限界にも到達しやすい。だがグリッドバッチはバッチ処理をサーバ単位に分散したうえで、サーバ間で並列化することで高速化を実現する。高価な単一のサーバに代わって多数の安価なサーバを活用できるため、より有効にITリソースを活用できる。また処理能力が不足してきた場合でも、サーバを必要に応じて追加するだけで柔軟に対処が可能だ。
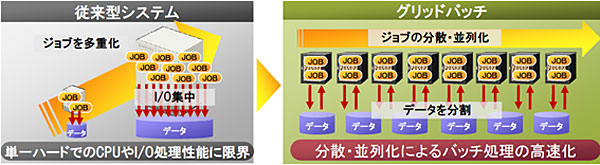 グリッドバッチは処理時間を大幅に短縮し、コストや可用性の面でも優位性がある。
グリッドバッチは処理時間を大幅に短縮し、コストや可用性の面でも優位性がある。
信頼性においても、単一ハードでは障害時に待機系への切り替えなどが必要だったが、グリッドバッチであれば常に複数台のサーバが並列で稼動しており、マシントラブルがあっても自動的に他のサーバに処理を移行して継続できるため障害範囲を局所化することができる。これによりエラー部分だけの再実行をすればよいため、実行時間の短縮に貢献する。
加えて、プライベートクラウドへの適用が可能であることも大きな優位性だ。クラウドに適用することで、業務量に応じ柔軟にシステム規模を変更できる。例えば日中はオンライン用、夜間はバッチ用など、業務の負荷変動に応じてITリソースを活用できるわけだ。
 プライベートクラウドでのグリッドバッチ適用イメージ
プライベートクラウドでのグリッドバッチ適用イメージ
 高速バッチ処理のメリット、適用範囲、ユースケース--プライベートクラウド適用例も
高速バッチ処理のメリット、適用範囲、ユースケース--プライベートクラウド適用例もグリッドバッチを業務推進の武器に
グリッドバッチの適用で恩恵が期待できるのは、基本的には大量データの分割が可能な業務だ。以下のような場合に効果が大きい。
- 大量で、かつ分割可能なデータ(データレコード間に依存関係がない)
- 並列化可能な繰返処理や逐次処理(プログラムを分割または再利用可)
- 業務視点で分割可能(処理効率の向上、障害時の業務影響範囲の局所化が可能)
具体的には、DB更新の夜間バッチ、銀行など金融機関の振込み一括バッチ処理ほか、全国展開のフランチャイズチェーンの売り上げ・在庫管理システムの月次バッチ処理などが挙げられる。いっぽう適用が難しいのは、ファイル全体を何度も読み書きするような、入出力ファイルを分割できないケースだ。
Hadoopとの関係—それぞれ異なる狙い
なお、オープンソースの大量データ処理フレームワーク「Hadoop」も、グリッドバッチと同等な並列処理が可能だ。だが両者の間には「ねらいの違い」という差異がある。グリッドバッチが実現するのはデータ分割の柔軟性、COBOLなどの既存資産を活用した開発、ジョブ障害の局所化による終了時間の厳守などといった利点だ。いっぽうHadoopは、基盤インストール/セットアップの容易性や、開発性/周辺開発ツールの拡充などを特徴としている。
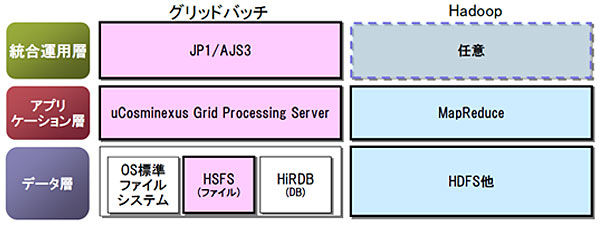 同等な並列処理を実現するが、狙いはそれぞれ異なる
同等な並列処理を実現するが、狙いはそれぞれ異なる
なお、より詳細な資料をダウンロードする事で、ここまでの記事内容をより具体的・詳細に確認できるほか、グリッドバッチ処理を提供する具体的製品である「uCosminexus Grid Processing Server」の概要を知ることができる。高速化を実現するスケジュール機能、処理の平準化を図るスケジューリング方式についての記述などもあるので、データ処理の今後を考える企業担当者の方は、ぜひご参考にして頂きたい。





