
生成AIの台頭により、企業のDXは新たな局面を迎えている。多くの企業がAIによる業務効率化や営業戦略の高度化を模索しているが、その成否を分ける決定的な要因は、最新のAIモデルの選択ではない。実は、その前段にある「企業データ基盤」の設計思想そのものにある。
従来のデータ活用は、人間が理解するための「整理」に主眼が置かれてきた。しかし、AIが自律的に判断し、戦略を支援する時代においては、データには「正確さ」に加え、AIが解釈可能な「構造」という新たな要件が加わっている。本稿では、日本最大級の企業データベース「LBC」を展開するユーソナーの知見に基づき、AI時代に求められる「キレイなデータ」の本質と、営業競争力を劇的に高めるデータ基盤のあり方について深く掘り下げていく。
営業戦略のパラダイムシフトと「データの正体」
不確実性が高く、変化の激しい現代の事業環境において、伝統的な「足で稼ぐ」営業や、ベテランの「勘と経験」に頼る手法は限界を迎えつつある。持続的な成長を実現するためには、客観的かつ合理的な判断に基づいた「データドリブンな営業戦略」が不可欠な考え方となっている。データに基づいた意思決定は、単に営業組織の生産性を向上させるだけでなく、顧客ニーズの的確な把握や迅速な意思決定を可能にするからだ。
しかし、ここで多くの企業が陥る誤解がある。それは「データの量」さえ確保すれば、精度の高い戦略を描けるという思い込みだ。結論から言えば、戦略の成否を左右するのはデータの総量ではない。重要なのは、正しく整理され、常に最新性が保たれ、そして活用目的に応じて使いやすく加工された「キレイな顧客データ」の存在である。
特に、生成AIの活用が本格化する現在、このデータの質がもたらす格差は、企業の競争力に直結する死活問題となっている。AIは膨大な情報を処理する能力を持つが、その入力値(インプット)となるデータの質や構造が不適切であれば、期待される成果を得ることはできない。営業戦略においても、AI活用においても、すべての出発点はやはり「キレイな顧客データ」にあることを再認識すべきである。
日本企業が直面する「データ活用」の冷酷な現実
ユーソナーが実施した最新の調査によれば、新規市場開拓に積極的な企業の約7割が、優先ターゲットの選定やアカウント・ベースド・マーケティング(ABM)戦略において顧客データを活用していると回答している。一見すると、データ活用は日本企業に浸透しているように思える。
しかし、その実態を深掘りすると、深刻な課題が浮き彫りになる。約半数の企業が自社の市場シェアを正確に把握できておらず、自社の強みを発揮すべき市場を特定できていないという結果が明らかになったのだ。営業現場では依然として以下のような課題が山積している。
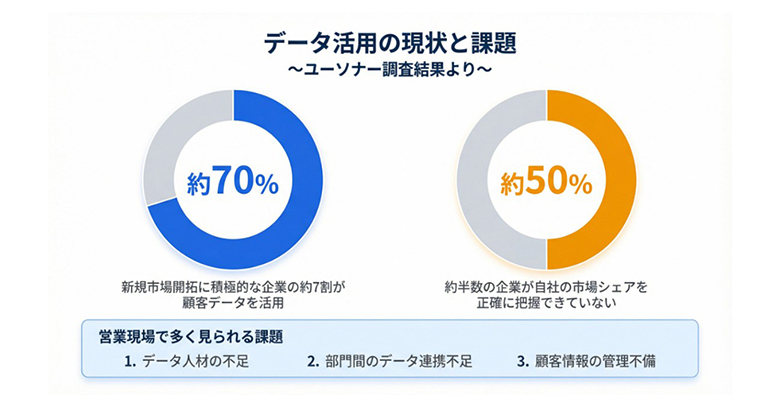
出典:BtoB企業の市場開拓におけるデータ活用の実態を調査
その結果、現場では「有望そうだから訪問する」といった直感頼みの営業が繰り返され、十分な根拠のない優先順位付けや非効率なアプローチが生まれている。成功事例や失注要因が組織内で十分に共有されず、属人的な営業活動が温存される構造は、もはや日本企業の慢性的な課題といえる。
「キレイなデータ」が営業の再現性を生むメカニズム
顧客データが「キレイ」に整備されている状態とは、単にリストを保有していることではない。それは、営業活動を属人的な「職人芸」から、組織として「再現性のあるプロセス」へと昇華させるためのインフラである。
データが整備されていれば、営業担当者は訪問前に企業属性や過去の接点を把握した上で活動を開始できる。さらに、取引情報やリード情報が統合されていれば、業種や企業規模ごとの成約傾向を分析し、真に成約確度の高いターゲットを精密に抽出することが可能になる。
特筆すべきは、企業の「点」の情報ではなく「線」の情報を捉えられる点だ。過去から現在に至る活動履歴や、将来に向けた投資の方向性までをデータで捉えられれば、顧客が抱えるニーズの緊急度までも精度高く推察できるようになる。この「予測の精度」こそが、現代の営業戦略における武器となる。
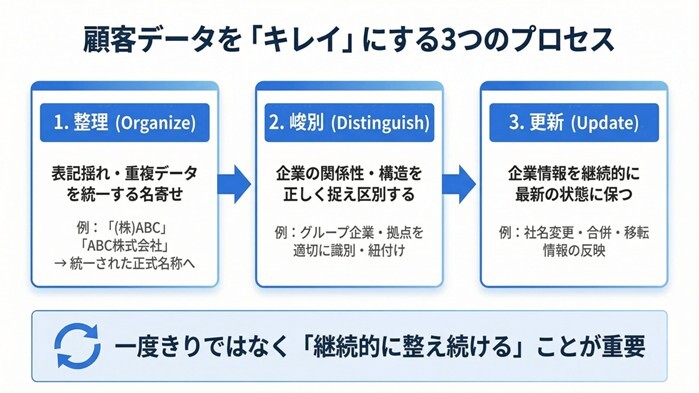
顧客データを「キレイ」に保つためには、3つのプロセスを継続的に行うことが不可欠である
AI時代に問われる「構造化」という新たな分水嶺
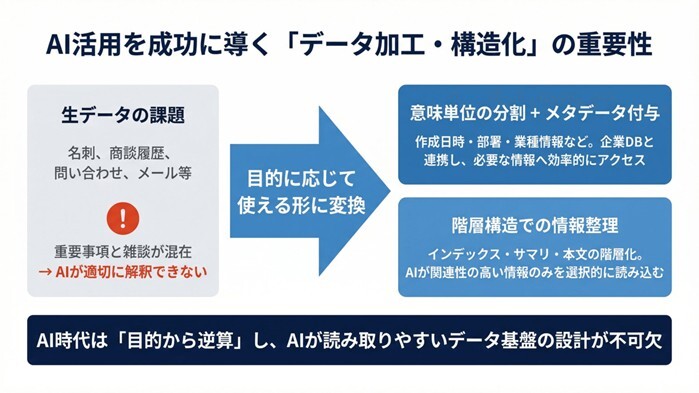
AI活用が進む今、データに求められる要件はさらに一段高まっている。もはやデータが正しいだけでは不十分なのだ。今、企業の命運を握るのは、データが「AIが参照しやすい形に加工・構造化されているか」という点である。
多くの企業は、名刺情報、商談履歴、問い合わせ、メール履歴といった多様なデータを保有している。しかし、これらを生データのままAIに渡しても、期待通りの成果は得られない。人間であれば文脈で理解できることでも、AIにとっては重要事項と雑談が混在した状態では、適切に解釈できない場合があるからだ 。AIの出力品質は、モデルそのもの以上に、どのようなデータをどのような構造で与えるかに大きく左右される。
具体的には、以下の設計が求められる。
① 意味単位の分割とメタデータの付与
膨大なテキスト情報を、意味のある単位で適切に分割し、そこに作成日時、部署、業種・企業属性といったメタデータを付与する。さらに、これらを企業データベースと連携させることで、AIは必要な情報へ効率的にアクセスし、精度の高い回答が可能になる。
② 階層構造による情報の整理
AIエージェントが自律的に情報を探索するような活用では、情報を「インデックス」「サマリ」「本文」という階層構造で整理しておくことが重要である。情報の入口となる要約が整備されていることで、AIは関連性の高い情報のみを選択的に読み込み、効率的な意思決定を支援できるようになる。
つまり、AI時代のデータ基盤とは、活用目的から逆算して「AIが読み取りやすく、必要な情報にたどり着きやすい形」に設計された戦略的な基盤であるべきなのだ。
ユーソナーが提供する「LBC」:日本最大級の企業データ基盤
AI活用の成果を左右するのは、モデルの性能ではなく、その前段にある「企業データ基盤」と「データ加工の設計力」に他ならない。この領域において、ユーソナーが提供する法人企業データベース「LBC」は、国内最大級のデータ基盤として重要な役割を果たしている。
LBCは、日本全国約1250万拠点の事業所に11桁の管理コードを付与し、企業の属性情報を網羅的に保持している。その強みは、単なる最新情報の提供にとどまらず、登記簿などのオフラインデータからWeb上の情報まで、120項目以上の情報を統合・蓄積している点にある。
ユーソナーの強みは以下の点に集約される。
- 圧倒的な名寄せ・統合能力:企業名の表記ゆれ、社名変更、過去の変遷履歴までを長年蓄積しており、正確な「名寄せ」を継続的に実行できる。
- 系列構造の可視化:法人番号、業種、売上規模だけでなく、資本系列や本社・事業所の関係性まで把握可能だ。これにより、系列構造まで含めたアカウント戦略の策定を支援する。
- AIフレンドリーなデータ供給:API等を通じて、業務システムからLBCを直接利用し、企業データの管理・更新・検索を自動化できる。この「自動化された最新基盤」があるからこそ、その上に営業ナレッジを重ね、AIが参照しやすい形へと加工していくことが可能になるのである。
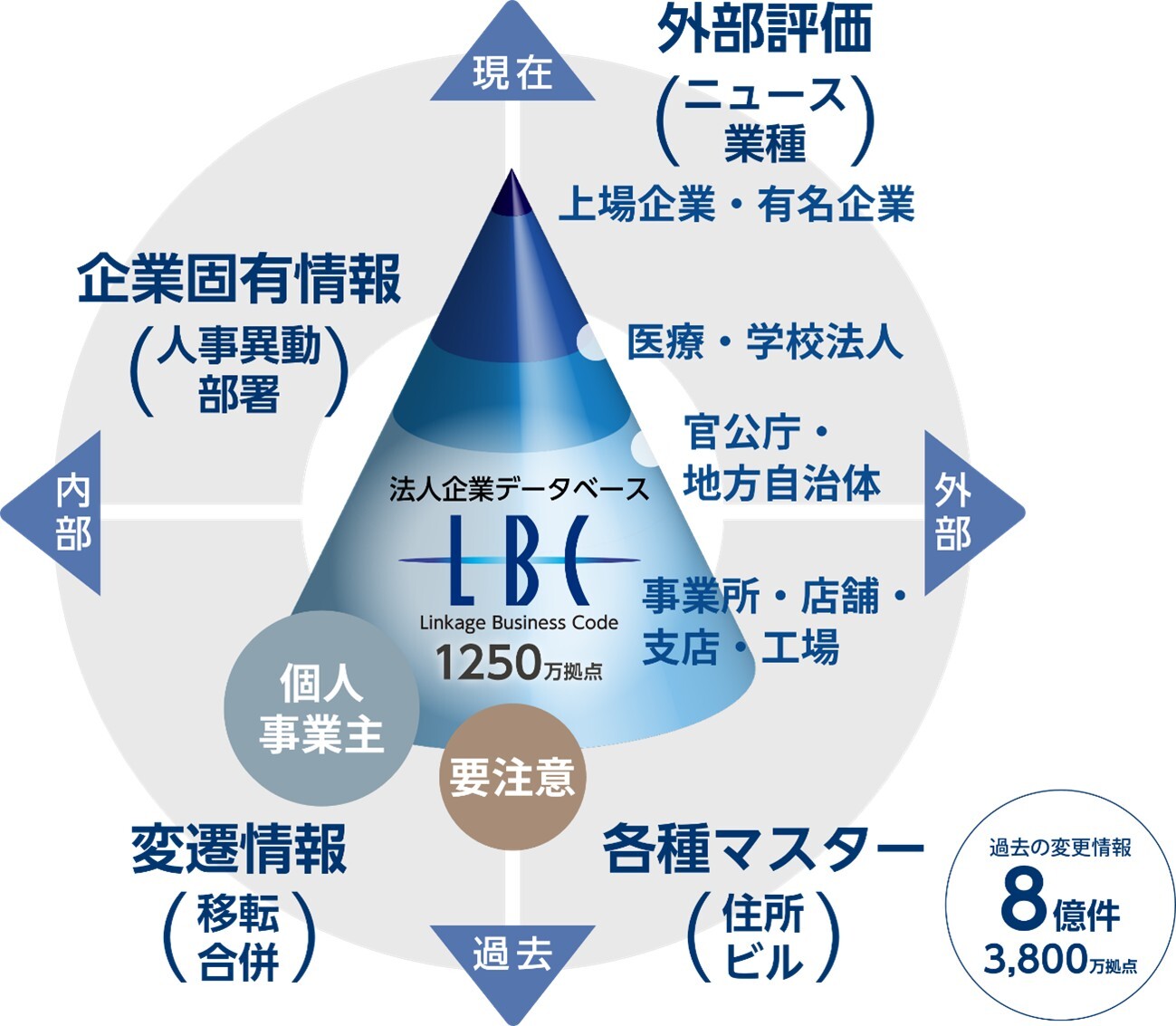
さらに、LBCは業種、売上高、従業員数をはじめとした多様な属性情報を体系的に保有している。これらは単なる付加情報ではなく、AIが企業の状況やニーズを判断するための重要な情報である。すなわち、LBCはデータを“キレイに整える基盤”であると同時に、“AIが意思決定に直接活用できる形へと変換する基盤”として機能する、日本最大級の企業データ基盤である。
データ基盤こそが「次世代の競争力」の源泉である
人手不足や働き方の変化が進む中、限られた時間で成果を最大化することは、あらゆる企業にとって重要な経営課題となっている。営業の生産性を劇的に高めるのは、単なる自動化ツールではない。顧客データをただ保有するだけでなくAI活用を見据えて「使える形」に構造化されたデータ基盤そのものである。
データの整理、峻別、更新、そして活用目的に応じた加工や構造化——この一連のプロセスを設計できるかどうかが、今後の競争力を大きく左右するだろう。営業戦略を高度化し、AI活用を成果につなげるために、まず取り組むべきは、足元の企業データ基盤を盤石なものへと整えることだ。キレイで、使いやすく、更新され続けるデータこそが、これからの企業活動を支える揺るぎない土台となるはずだ。
日本最大級の法人企業データを搭載した「ユーソナー」の詳細はこちら





