
「Apache Spark」は、データエンジニアリングや機械学習のワークロード用の非常に人気が高い実行フレームワークだ。Databricksのプラットフォームに利用され、「Azure HDInsight」「Amazon EMR」「Google Cloud Dataproc」など、オンプレミスとクラウドベースの両方の「Hadoop」サービスで利用できる。また、「Mesos」クラスタでも実行できる。
だが、Mesosを使わず、「Hadoop YARN」の文字列を付加することなしに「Kubernetres」(k8s)クラスタでSparkのワークロードを実行したい場合はどうなのだろうか?Sparkはまず、バージョン2.3のリリースでKubernetes固有の機能を追加し、バージョン2.4でそれを改善したが、完全に統合された方法で、Sparkをk8sでネイティブで実行させるのは、まだ難しい場合がある。
Kubernetes Operator
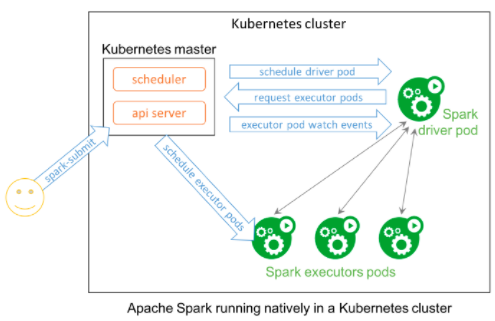
Kubernetesの開発元であるGoogleは米国時間1月30日、Apache Spark向け「Kubernetes Operator」(略して「Spark Operator」)のベータ版リリースを発表した。Spark Operatorは、Sparkがk8sクラスタでネイティブに稼働できるようにし、分析用、データエンジニアリング用、機械学習用のSparkアプリケーションを、Sparkのインスタンスと同じように、これらのクラスタにデプロイできる。
提供:Google
Googleによると、Spark Operatorは、Sparkアプリケーションの宣言的仕様にカスタムリソースを使用するKubernetesカスタムコントローラだ。自動再起動やCronを使って実行時間を指定されたアプリケーションもサポートしている。また、開発者やデータエンジニア、データサイエンティストは、Sparkアプリケーションを記述する宣言的仕様を作成したり、アプリケーションを管理するためにネイティブのKubernetesツール(「kubectl」など)を利用したりできる。
30日にリリース
Spark Operatorは、「Google Kubernetes Engine」(GKE)に簡単にデプロイできるように、「Google Click to Deploy」コンテナの形で、Kubernetes用「Google Cloud Platform(GCP)Marketplace」から入手できる。だが、Spark Operatorはオープンソースプロジェクトなので、どのようなKubernetes環境にもデプロイでき、同プロジェクトのGitHubサイトでは、「Helm」のチャートを使ったコマンドラインによるインストール手順を提供している。
この記事は海外CBS Interactive発の記事を朝日インタラクティブが日本向けに編集したものです。





