
富士通研究所は、暗号化されたデータベースから元データの類推を防止することで、より安全にデータベースと検索内容を照合できる技術を開発したと発表した。データベースに最小限のダミーデータを追加することで、データベース上の登録数を攪乱し、元データの類推を防止することができる。
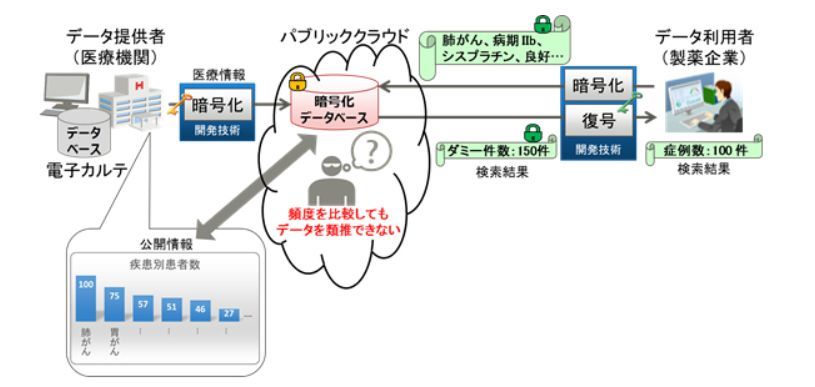
開発したデータの類推を防止する技術
暗号化されたデータベースでも、公開された統計情報などと比較することで、登録数の一致などから元データを推定される危険性がある。今回開発された技術により、クラウド上などさまざまな場所で管理されるパーソナルデータや機密データを暗号化させたデータベースを、さらに安全に活用することが可能になる。
従来パーソナルデータや機密データを安全に扱うために、データベースに登録するデータと利用者側が入力する検索文字列を、暗号化したまま照合できる秘匿検索技術が開発されていた。しかし例えば、医療分野では公的機関や医療機関が公開している病名や医薬品などの統計情報と、データベースに登録されている件数を突き合わせることで、暗号化したデータベースであっても、そのデータの内容を類推できてしまう問題が指摘されていた。
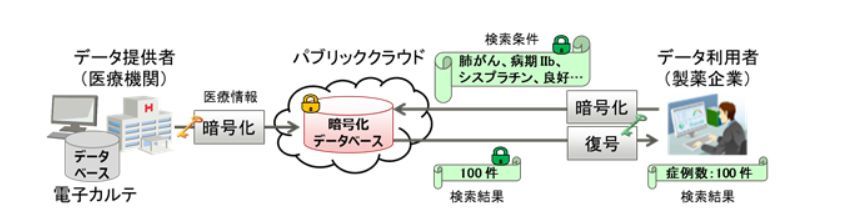
従来の秘匿検索技術による医療データの利活用イメージ
さらに、データベースの内容が類推できてしまうと、検索文字列が暗号化されていても、検索結果から利用者が何を検索したのかも推定できてしまうため、データ提供者および利用者にとって、クラウドなどさまざまな場所で管理されるデータベースをより安心して使えるようにする必要があった。
元データの類推を防ぐ方法としては、データベースにダミーデータを追加する方法がある。しかし、一般的なダミーデータの追加方法は、最も件数が多い項目に合わせる形で他の項目に対してダミーデータを追加していくため、最大件数とデータの種類に応じて、データベースに登録されるデータ量が数百倍以上に増加してしまうという課題があった。
今回開発した技術では、医療用データを例にすると、病名、医薬品、血液型といったデータの項目ごとにグループを作り、そのグループごとにダミーデータを入れていく。各グループ(例:血液型)の要素(例:A型、B型、O型、AB型)の数がそれぞれ均一になるようにダミーデータを登録していくことで、それぞれの要素がデータベース上ではすべて同じ数で出現し、類推をすることができなくなる。

登録数が攪乱されたデータベースの構造
またデータ量増加の抑制については、グループ内の要素の数が均一になるように、グループごとに最小限の数のダミーデータが作成されることで実現できる。検索結果に含まれるダミーデータの件数は、独自のルールで作成されたフラグを照合することで容易に除外できるため、利用者には処理された後の正しい検索結果が提供される。
富士通研究所では同技術を使い、2000項目からなる診察記録10億件をデータベースに登録したところ、データ量の増加を元データの9倍以内に抑え、統計情報と登録数が一致せず類推できない状態で照合ができることを確認できた。
今後は、データの匿名化技術やプライバシーリスクの評価技術など、富士通や富士通研究所のセキュリティ技術と組み合わせて提供していくことを検討する。





