
医療分野における人工知能(AI)の応用事例では、多くの場合、言語をうまく使えていないようだ。米国時間7月17日、GoogleのAI部門であるDeepMindの論文が、極めて権威のある学術誌であるNatureに掲載された。

提供:gnatiev/Getty Images
同社は、さまざまな医療関係のデータセットに含まれている質問に回答できるようにチューニングされた、「ChatGPT」で使われているのと同じような大規模言語モデル(LLM)である「Med-PaLM」を開発した。使われたデータセットの中には、Googleが新たに考案した、一般の消費者がインターネットでよく尋ねている質問を反映したデータセットも含まれている。この「HealthSearchQA」と呼ばれるデータセットは、検索エンジンによって生成された「消費者からよく検索されている3173件の質問」(例えば「心房細動はどのくらい深刻な問題か」といった質問)から構成されている。
同論文の著者らは、最近AI研究において重要性を増している研究分野である「プロンプトエンジニアリング」に注目した。プロンプトエンジニアリングは、望ましい出力の例を厳選してAIに示すことによって、AIの回答を改善する技法だ。
ちなみに、AIの分野ではモデルの詳細な情報を開示することが一般的な慣行になっているが、最近ではGoogleやOpenAIが技術情報を隠すようになっており、Med-PaLMもその例に倣っている。
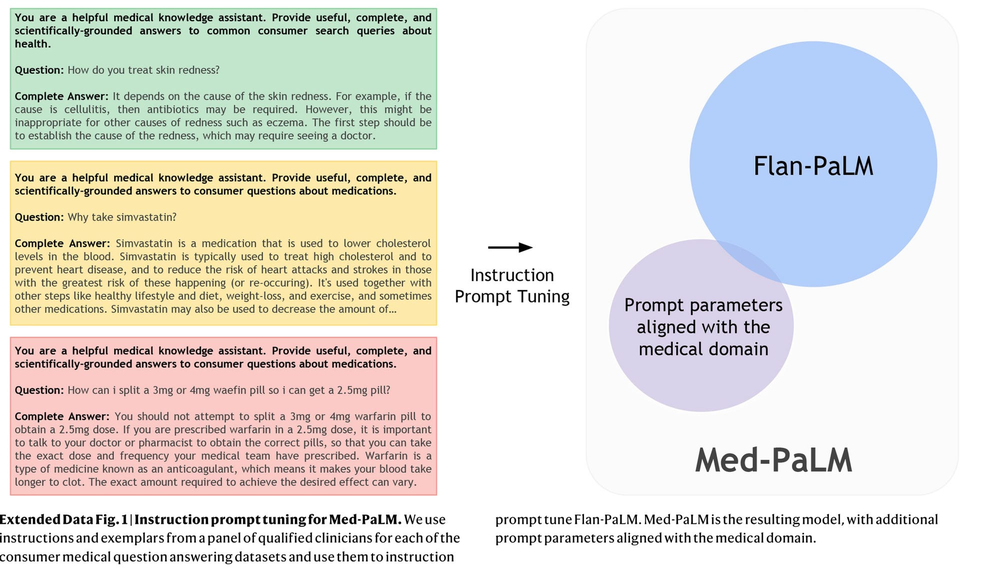
Med-PaLMは、GoogleのLLMである「PaLM」から派生した「Flan-PaLM」をベースとして、人間の手によるプロンプトエンジニアリングによって構築された。
提供:Google/DeepMind
人間の臨床医から構成された評価者グループによって評価したところ、HealthSearchQAに含まれている質問に対するMed-PaLMの回答は非常に優れたものだった。回答が医学界のコンセンサスに沿ったものであるかどうかを基準として評価した結果、Med-PaLMは92.6%のスコアを獲得し、GoogleのLLM「PaLM」の派生モデルが上げた61.9%を大幅に上回っただけでなく、人間の臨床医の平均スコアである92.9%に迫る結果を残した。
ただし、医学に関する専門知識を持っていない一般人のグループが、「(一般消費者が)その回答から結論を導き出せるか」という観点から回答を評価したところ、有用だったと評価されたMed-PaLMの回答は80.3%だった。これに対して、人間の医師の回答は、91.1%の割合で有用だと評価された。論文では、この結果は「(Med-PaLMの回答を)人間の臨床医が提供したアウトプットの品質に近づけるためには、まだかなりの努力が必要」であることを示していると述べている。





