ディー・エヌ・エー(DeNA)のデータサイエンスグループは今や日本トップレベルのKagglerたちが集結する場となっています。このグループに配属となった2018年度 新卒入社の田口直弥はそれまでKaggleに縁もゆかりもなく、また元々データサイエンスに強い関心があったわけでもありません。
今回はそんな田口がDeNAのデータサイエンスグループに配属された経緯やそこで半年を過ごした体験をもとに、Kaggleのトッププレーヤーたちと働く様子やデータサイエンティストという職種の魅力を非Kaggler的な視点から共有します。
Kaggle Masterの巣窟に流れ着いた経緯
私(田口)は大学院で機械学習分野の研究をしていたこともあり、元々は機械学習エンジニアを目指していたのですが、幾つかのインターンシップなどを経て、この職種、というよりエンジニア自体が自分にはあまり向いていないという認識を持ちました。
というのも、インターン先の優秀な同期や社員のエンジニアを見ているとその多くが技術そのものへの関心が非常に高く、プライベートな時間を自己研さんや趣味を兼ねて新しい技術のサーベイなどに使っている反面、私にはそれが苦痛になるだろうと感じたためです。
プライベートな時間を自己研さんも兼ねて過ごすこと自体には抵抗がないのですが、興味の対象が技術そのものというよりそれを使って得られる知見やそれを使って実現するビジネスにありました。
また、進路を決める上では自分の強みを生かせるか否かも重要だと思います。私自身は「状況を俯瞰(ふかん)的に見て構造化する力」や「必要十分な情報量でコミュニケーションをとる力」に強みがあると捉えており、これらはエンジニアとして働く上でも生きると思いますが、より親和性が高いのはいわゆるビジネス寄りの職種だと考えていました。
上記のような背景があり、結局就職活動ではエンジニア以外の職種を多く受けていました。実は当初、DeNAにもビジネス職として応募していたのですが、工学系出身であることや機械学習の分野で研究を行っていたというバックグラウンドをできるだけ生かしたいという考えを人事部に相談したところ、データサイエンティストとしてデータサイエンスグループに配属となりました。後述しますが、データサイエンティストという職種はさまざまな価値の出し方があり、自分の興味や強み、これまで培ってきた力をうまく生かして働ける職種だと思っています。
それまでKaggleのコンペに参加したことは一度もありませんでした。また、データサイエンスという領域を強く意識したことがなく、Kaggle Masterの巣窟に入ると知ったときは生きた心地がしませんでした。しかし、実際に働いてみるとKagglerの皆さんは人当たりが良く、学ぶことも多くありました。この職種はまさに自分が求めていたものだと感じています。
Kaggleのトッププレーヤーに囲まれて働く日常
DeNAのデータサイエンスグループには、下図のように日本のKagglerの中でもトッププレーヤーが多く集まっています。ここではその日常やそこで得られる学びについて共有します。
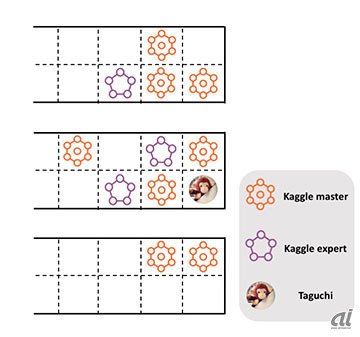
田口の座っている席の周囲(10月29日現在)
同じプロジェクトの担当者とは普段から一緒に仕事をすることが多く、チームでのサービスの作り方やデータに基づくコンサルティングの進め方、データサイエンスの専門技術や考え方など、さまざまなことを近くで学んでいます。
特に機械学習の応用に関しては学びが多くあります。私の担当プロジェクトは機械学習の利用を前提としていないのですが、Kagglerの手にかかると手段の一つとして当たり前のように機械学習が使われるのです。この半年で主に次のような学びを得ました。
- 機械学習の利用を見据えたデータの加工や蓄積の推進の仕方
- 機械学習を用いた際の性能の見積もりとそれを使うか否かの判断
- 利用する機械学習モデルの選択や解釈の仕方
- 上記全体を加味した他職種のプロジェクトメンバーとのコミュニケーション
(1)については、どの企業にもさまざまなデータがあると思います。しかし、十分な種類・量のデータが利用しやすい形で蓄積されているケースはほとんどないのではないでしょうか。データサイエンティストが先導して機械学習の利用を見据えたデータの加工や蓄積を行うようにプロジェクトを進めるのは非常に重要なスキルです。
次は(2)についてです。何でも機械学習を使えばいいというものでもなく、使うべきところで使うという判断をする必要があります。その判断を行うためには機械学習を使った場合の性能の見積もりをする必要がありますが、Kaggleで多様なデータや機械学習モデルの評価指標に触れていると、ある種の「アタリの付け方」を身に付けられると思います。
また(3)については、ビジネスで機械学習モデルを使う際にはその解釈性、つまりモデルの出力に対する理由を説明できるか否かが非常に重要になります。このモデルの出力を解釈する方法や、それらを見据えたモデルの選択が重要です。
最後に(4)について、機械学習モデルのサービスへの組み込み方をエンジニアと相談したり、AIにできることとできないことについて期待値を適切にコントロールしながら事業担当者とコミュニケーションするのは最も重要な作業となります。
また、プロジェクトに関わっていない同僚とも、週次の定例会で議論したり、座席の近くで雑談したりすることはよくあります。Kaggleや機械学習に関する話題が多く、検証用データ(注1)の作り方や特徴量エンジニアリング(注2)の仕方、LightGBM(注3)の内部で使われているアルゴリズムなど実用的な話になることもありますし、Kaggleやデータサイエンスのコミュニティーについて話すこともあります。私自身はまだ分からないことも多く、話しに付いていけないこともありますが、非常に刺激的で良いインプットになっていると感じています。
注2:機械学習モデルに入力するデータを人手であらかじめ加工すること。これにより、機械学習モデルが自動で学習できないようなデータの特徴を表現できる。
注3:Microsoftが開発した勾配ブースティングアルゴリズムを使った機械学習モデル。Kaggleでよく使われている。





