
Metaは米国時間4月10日、「訓練および推論アクセラレーター」(Training and Inference Accelerator:MTIA)チップの第2世代を発表した。第1世代の登場からほぼ1年後の発表であり、同チップに新たに加えられた部分は大幅なパフォーマンス向上をもたらしたと同社はアピールする。
Metaは、Microsoft、Google、Teslaといった大手テック企業同様、カスタム人工知能(AI)ハードウェアに資金投入することでGPU大手サプライヤーNvidiaの独占力を回避しようとしている。また、資金投入は、生成AIに対する関心が急激に高まる中でNvidiaが需要に対して十分な量のチップを製造できていないことを考慮し、コンピューティングの供給を確保するための手段でもある。
最初のバージョン同様、MTIAバージョン2チップは、メッシュ状の並列動作する回路ブロック「8X8グリッドのプロセッシングエレメント(PE)」で構成される。MTIA v1の3.5倍高速で動作するとMetaはアピールする。変数の値がゼロである「スパース」演算のようなAIタスクは7倍高速で実行するという。
このような性能向上の背後にあるのは、チップのアーキテクチャーに対する変更、メモリーとストレージの増加だとMetaはいう。「ローカルPEストレージのサイズを3倍、オンチップSRAMを2倍、帯域幅を3.5倍、『LPDDR5』の容量を2倍にした」(同社)
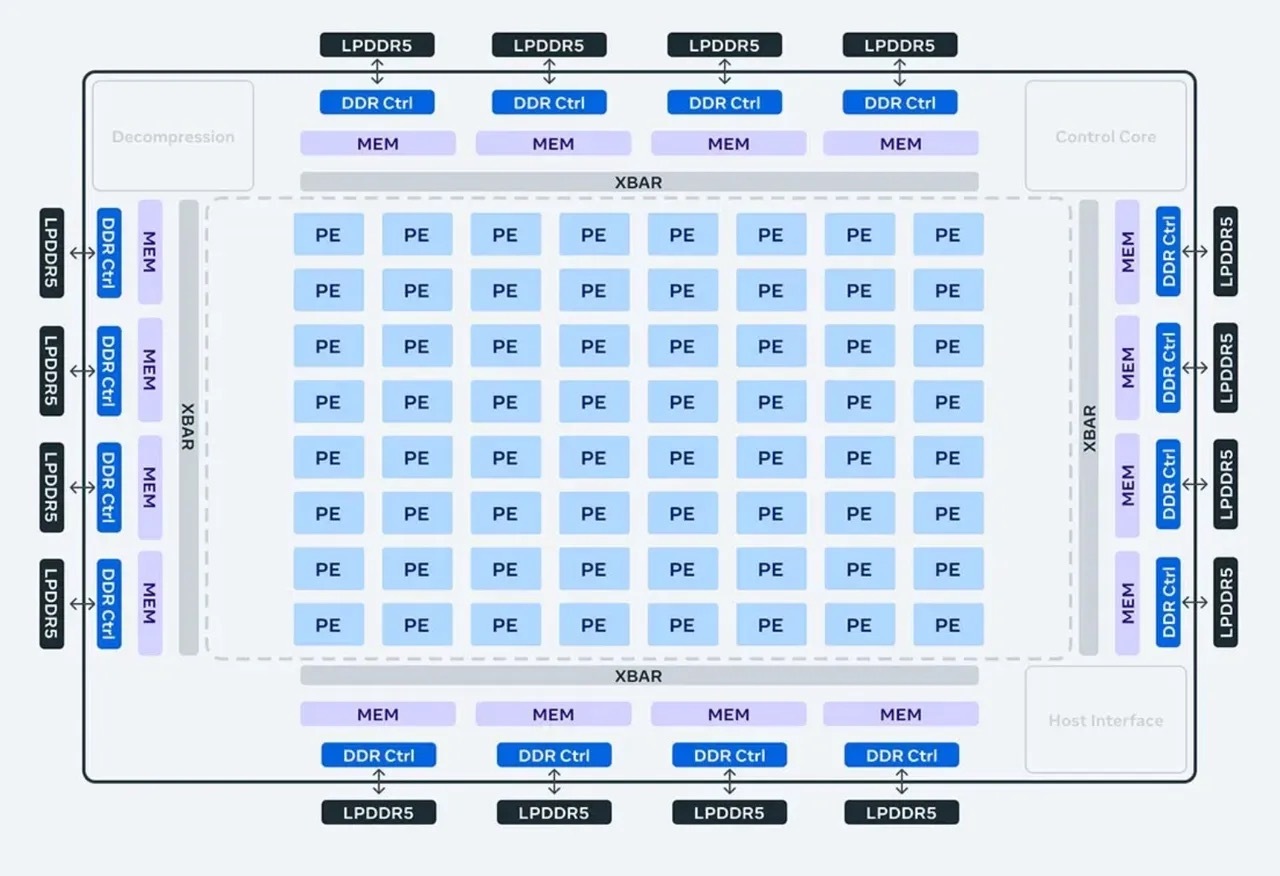
MTIA v2のアーキテクチャー図。
提供:Meta
同チップは、コントラクトチップメーカー大手Taiwan Semiconductor Manufacturingが開発した5ナノメートルプロセス技術で製造されている。
バージョン1の373平方ミリメートルに対して421平方ミリメートルと大型化したバージョン2は、24億ゲートを搭載し、毎秒1億300万回の浮動小数点演算の実行が可能とMetaは語る。前世代では11億ゲートと6500万演算だった。

MTIAの世代別比較。
提供:Meta
MTIA v1同様、オープンソースの開発者フレームワークでMetaが開発した「PyTorch」を使ってプログラムを最適化するソフトウェアを実行する。2つのソフトウェアコンパイラーが連携しており、フロントエンドのソフトウェアは、プログラムの計算グラフをコンパイルし、バックエンドにあるソフトウェアは、オープンソースの「Triton」コンパイラー言語で書かれ、チップに最適なマシンコードを生成する。
MTIA v1向けのソフトウェア開発作業により、新しいチップを迅速に実現できたという。「最初のシリコンから16リージョンで稼働する量産モデルへと9カ月未満で移行できた」とMetaは述べる。チップは、ランキングおよびレコメンデーション広告モデルを支援するために展開されているという。
Metaは、72基のMTIA v2を並列に動作させるラックマウント式のコンピューターシステムを設計している。「当社の設計は、高い演算能力、メモリー帯域幅、メモリー容量を備えた高密度の性能を提供することを可能にする」と同社はいい、「この密度は、より幅広いモデルの複雑性とサイズに簡単に対応することを確実にする」と続ける。
同社は、カスタムハードウェアデザインへの資金投入を継続する計画だ。「現在、複数のプログラムが進行中だ。それらは、MTIAの範囲を拡張することを目標としており、生成AIワークロードに対するサポートが含まれる」という。「既存インフラとともに、将来的に利用可能になると思われる新しくより高度なハードウェア(次世代の生成AIを含む)と連携して動作するカスタムシリコンを設計している」と同社は語る。

MetaのMTIA v2は、オンチップメモリーを2倍にし、AIタスクのパフォーマンスを3倍にする。
提供:Meta
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。





