
米Microsoftが2015年10月にプレビュー版の提供を開始したデータレポジトリサービス「Azure Data Lake」。IoTデバイスやウェブアプリケーションなどで生成されるさまざまな形式の大量データを1カ所に集約し、そのデータをHadoopで処理するための大規模並列ストレージサービス 兼 演算処理サービスをAzureから提供するものだ。同社がインターネット検索サービスBingを開発するために構築した社内システム「Cosmos」がベースになっている。Azure Data Lakeの概要について、同社 ビッグデータチームのMatt Winkler氏に話を聞いた。
Bing開発基盤はデータが無制限に増えることを想定して設計した

Microsoft プリンシパルプログラムマネージャー Matt Winkler氏
私が所属するMicrosoftのビッグデータチームでは、大きく2つのシステムを作っています。1つは社内向けのシステム「Cosmos」、もう1つはAzureを通してビッグデータを使ってもらうための顧客向けのクラウドサービス群です。今回紹介するAzure Data Lakeは、われわれのチームの2つの事業を合わせたもので、社内システムのCosmosをベースにしたデータレポジトリサービスを、Azure上で顧客向けに提供しています。
まず、Cosmosについて説明しましょう。もともとCosmosは、約10年前、当社がBingのアプリケーションを開発するために構築した基盤でした。インターネット検索エンジンは、インターネット上のデータのコピーを取り、そのデータへの質問に対してインデックスを作成して回答する仕組みを、アプリケーションを通じて提供するものですが、Cosmosの基盤上では、ウェブサイトのコピーの保存と、インデックス作成のための開発、インデックスの改良を行っています。
このような基盤を設計するにあたり、われわれはあらかじめ、Cosmosに入れるデータが無制限に増えることを想定しておく必要がありました。つまり、ストレージノードとコンピュートノードを経済的にスケールアウトできるようにするということです。さらに、スケールアウトする環境でプログラムを並列化することは大変なので、小さいシステムに書いたコードを動的にスケールアウトさせることも必要でした。Cosmosはこの要件を満たすシステムであり、今では、Xbox、Office 365、Azureなど、Microsoftの事業のシステムのすべてがCosmos上にあります。
例えば、社内からクラウドサービスがどう使われているかといったデータをCosmosから確認したり、そのデータをアナリティクスする基盤として利用したりしています。(研究開発部門の)Microsoft Researchは、画像処理のアルゴリズムの研究にCosmosを利用しています。
Azure Data Lakeを構成する3つのシステム
Cosmosを外部向けの有償サービス化したのがAzure Data Lakeであり、「Data Lake Store」「HDInsight」「Data Lake Analytics Service」の大きく3つのシステムで構成されています。
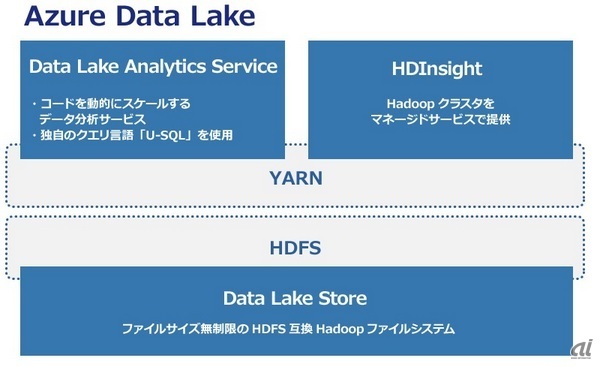
Azure Data Lakeの構成
Data Lake Storeは、Hadoop分散ファイルシステム(HDFS)と互換性のあるファイルシステムであり、ファイルサイズに制限なく格納できる大規模並列ストレージサービスを提供します。HDFSのAPIでデータを出し入れし、どんな種類のデータも、要件やスキーマを定義する前に取りあえずData Lake Storeに入れておくことが可能です。保存されたデータは、Azure Active Directoryによるアクセス制御やシェアの制御などで保護されます。
Azure Data Lakeの中で、HDInsightとData Lake Analytics Serviceは、Hadoopクラスタのリソース管理とジョブスケジューリングを担う「Apache YARN」上にあり、それぞれHDFS互換のData Lake Storeと統合されています。
HDInsightは、Azure上のWindowsとLinux環境でHadoopを動作させるサービスです。Hadoopのほかにもフレームワークの「Apache Spark」やストリームデータ処理の「Apache Storm」、Hadoop上で稼働する分散データベース基盤の「Apache HBase」といったクラスタもマネージドサービスとして提供するものであり、ユーザーは各クラスタのメンテナンスをどうするかを気にせずにサービスとして利用することが可能です。
Data Lake Analytics Serviceは、HDInsightで実行するジョブを定義するコンポーネントで、「U-SQL」というSQLライクな独自のクエリ言語、コードが動的にスケーリングする仕様が特徴です。U-SQLは、SQL構文の中にC#のコードを入れ込んで拡張できるようになっており、ビッグデータ解析を行う上で生産性の高い言語と言えます。
これらの3つのシステムが連携し、Data Lake Storeに保管したビッグデータに対して、Data Lake Analytics Serviceでデータ型やフォーマットをどう定義してどのような演算処理を行うかといったジョブを記述し、HDInsightでそのジョブ実行するのがAzure Data Lakeの全体像です。
ストレージとコンピュータを分離して課金
Azure Data Lakeでは、ストレージリソースとコンピュータリソースを使った分だけ別々に課金します。ストレージは保管したデータ容量に応じて料金が発生し、コンピュータは実行されたジョブに対してのみ料金が発生します。ビッグデータワークロードを実行するためにコスト効率のよい課金体系だと言えます。
また、Azure Data Lakeは、Azureのビッグデータ関連サービス群をセットにしたスイート「Cortana Analytics Suite」のコンポーネントとしても提供します。
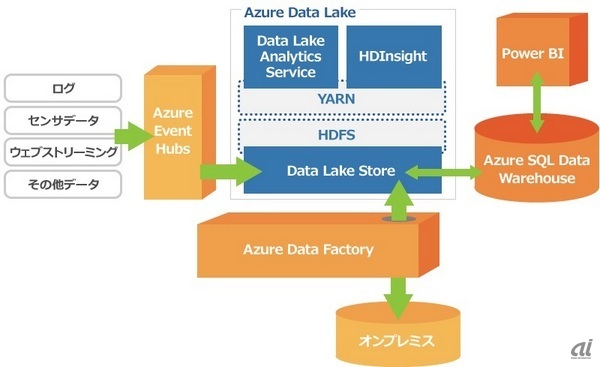
「Cortana Analytics Suite」でのAzure Data Lakeの構成
同スイートには、機械学習や自然言語処理、画像解析など分析サービスのほか、Azure Data Lakeに入れるデータをキューイングする「Azure Event Hubs」、オンプレミスとAzure Data Lakeの間でデータを移動する際の調整を行う「Azure Data Factory」、Azure Data Lakeと連携するデータウェアハウス(DWH)「Azure SQL Data Warehouse」とDWHのデータを可視化する「Power BI」までが含まれています。
Cortana Analytics Suiteで使う場合にはAzure Data Lakeに一定量のストレージがついてくる形になり、超過した分は課金されます。コンピュータリソースについては、単体と同様、実行したジョブに対してのみ料金が発生します。(談)





