
Apache Hadoopに関連するMicrosoft AzureのサービスとHortonworks製品についての勉強会が7月19日に開催された。この会は、世界39都市で行われているビッグデータ関連のミートアップコミュニティー「Future Of Data」の活動の一環として、日本マイクロソフトとホートンワークスジャパンの主催で実施されたもの。会場の日本マイクロソフト品川本社のセミナールームには約130人の聴講者が集まった。
「Data at Rest」と「Data in Motion」

ホートンワークスジャパン 北瀬公彦氏
まず始めに、ホートンワークスジャパンの北瀬公彦氏が、6月28~30日に米国San Joseで開催された「Hadoop Summit 2016 San Jose」のイベントを総括した。このイベントは、HortonworksとHadoopコミュニティが主催、Yahooが共催する形で毎年開催されており、第9回目となる今回は過去最多の4000人が参加したという。
今回のイベントでは、「Data at Rest(保存されたデータ)」と「Data in Motion(流れているデータ)」をシームレスに活用できる基盤“Connected Data Platform”がメインテーマだった。このような基盤を実現するために、クラウド上にデータ分析プラットフォームを展開するのが今後のトレンドであり、Hadoop/Sparkマネージドサービス「Azure HDInsight」や「Google Cloud Dataproc」が重要な役割を果たすとのこと。
尚、Hadoop Summit 2016 San Joseの様子は、北瀬氏がZDNet Japanに詳細なレポートを寄稿しているのでそちらをお読みいただきたい(テクノロジとプレーヤーが出揃った!北瀬公彦の「Hadoop Summit 2016」レポート)。また、10月26~27日には、日本初開催となる「Hadoop Summit 2016 Tokyo」が予定されている。
Microsoft + Hortonworksの3パターン
続いて、ホートンワークスジャパンの大浦譲太郎氏がHortonworks社と製品体系を紹介した。

ホートンワークスジャパンの大浦譲太郎氏
Hortonworksは、YahooでHadoopを開発していたエンジニアたちがスピンアウトして2011年に創業した企業。「Hadoop関連企業では上場第1号、オープンソースの企業としてはRed Hatに次いで上場第2号」(大浦氏)だという。コミュニティーで開発されたオープンソースのHadoopとその関連ソフトウェアを扱い、Hadoopディストリビューション「Horton Data Platform(HDP)」、データオーケストレーションツール「Apache NiFi」のディストリビューションであり、データフローマネジメント関連ツールなどをまとめた「Horton Dataflow(HDF)」を提供している。

ホートンワークスジャパンの今井雄太氏
HDPの利用形態のイメージとして、大浦氏はMicrosoftの製品サービスを組み合わせて使うケースを例示。(1)オンプレミスでHDP+SQL Server、(2)Azureの仮想マシン(VM)でHDPのライセンスを使う(Azure MarketplaceからHDP環境を設定済みのVMを立ち上げることができる)――の2パターンがあると説明した。加えてパターン(3)として、Azure HDInsightでは、HDPベースのHadoop/Sparkディストリビューションを従量課金のマネージドサービスとして利用できる。
Hadoopエコシステムで構築するConnected Data Platform
では、Hadoop Summit 2016 San Joseのテーマであった“Data at Rest”と“Data in Motion”をシームレスに活用するための基盤は、HDPとHDFでどのように構築するのか。次に登壇したホートンワークスジャパンの今井雄太氏が、オープンデータとして公開されているニューヨークの地下鉄の運行情報を使って、(1)リアルタイムに車両の位置情報や遅延状況を可視化する、(2)運行情報を蓄積して機械学習にかけ、未来の遅延を予測する――という2パターンのデータ分析を同一基盤上で実現する仕組みを例示した。それが下図だ。

保存されたデータと流れているデータをシームレスに活用するプラットフォーム
まず、路線ごとのID、電車ごとのID、タイムスタンプなどの運行データをNiFiによってニアリアルタイムで「Apache Kafka」へ連携させる。NiFiは、ウェブ、アプリケーションサーバ、センサなどさまざまなデータソースからの小規模データを別システムに渡すソフトウェアだ。Kafkaはメッセージハブと呼ばれるソフトウェアで、複数データソースからデータをpullで受け取り、複製分岐する。同じデータを何度も取り出して、別の処理フローに渡すことができるのが特徴だ。
ここで、Kafkaのメッセージの投げ先が、図中右上に向かう矢印(Data in Motionのフロー:Kafka→Spark Streaming→HBase→Spring→Web UI)と、右下に向かう矢印(Data in Restのフロー:Kafka→Spark Streaming→HDFS)の二手に分かれる。
- Data in Motionの処理フロー こちらでは、Kafkaからのデータを、ストリーミングデータを処理するSpark StreamingによるバッチでHBaseに格納し、Spring(これはHadoopではなくJavaアプリケーション)でWeb UIに表示している。そのWeb UIは下図のようなもので、リアルタイムに車両の位置情報、遅延情報を表示する。
- Data in Restの処理フロー もう一方では、KafkaからのデータをSpark StreamingでHDFSへそのまま書き出している。HDFSへ書かれたデータは、Apache HiveやSpark SQLなどで時系列分析をしたり、Sparkに組み込まれた「Machine Learning with Spark(Spark ML)」の機能をつかって機械学習をしたりできる。ここでは、Spark MLで機械学習した結果をもとに「Apache Zeppelin」(分析結果の可視化などデータサイエンティスト向けのUIを提供する)でモデルを書き、それを予測モデルマークアップ言語(PMML)でData in Motion側のフローへ送り込んでモデルを適用している。これにより、Data in Motion側では、Kafkaに入ってくるデータを教師データとして、“未来時刻に遅延が発生しそうな電車”をリアルタイムに予測することができる。
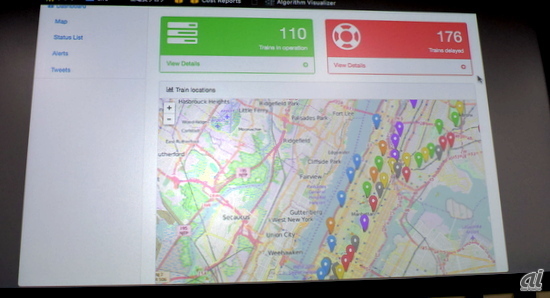
リアルタイムに車両の位置情報、遅延情報を表示
Azureならボタン一発でConnected Data Platformを構築

日本マイクロソフトの佐藤直生氏
このような“Data at Rest”と“Data in Motion”をシームレスに活用する仕組みは、Azure上ですでにマネージドサービスとして提供されており、テンプレートも用意されている。次に登壇した日本マイクロソフトの佐藤直生氏は、Hadoop/Sparkディストリビューション「HDInsight」を含むAzureビッグデータ関連サービス群と、それらのサービスをシナリオにそって組み合わせたテンプレート「Cortana Intelligent Solution Templates」を紹介した。
下図が、Azureのビッグデータ関連サービス群だ。HDInsightの周囲には、各種デバイスや業務システムなどさまざまなデータを受け取る「Azure Event Hub」、Spark Streamingのようにストリーミングデータへのバッチ処理を行う「Azure Stream Analytics」、HDFS互換のHadoopファイルシステム「Data Lake Store」、機械学習サービス「Azure Machine Learning」、データ可視化ツール「Power BI」などがある。
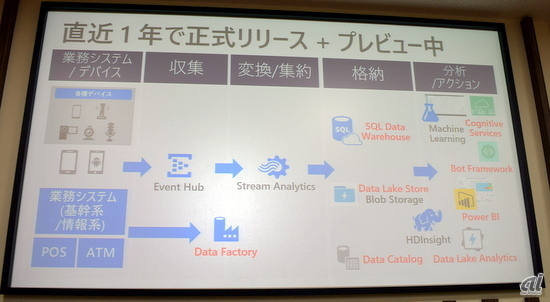
Azureのビッグデータ関連サービス(ちなみに、図中赤字で表示されているサービスはここ1年でリリースされたもの)
これらのサービスを組み合わせるシナリオを提供するのがCortana Intelligent Solution Templatesだ。「テンプレートのデプロイボタンを押すだけで、シナリオに含まれるサービス群をインテグレーションした環境が15~20分でできあがる」(佐藤氏)
佐藤氏は、Cortana Intelligent Solution Templatesの中から、飛行機の予兆保守のためのデータ分析を行うテンプレートを紹介した。ここでは、機体のデータをAzure Event Hub で受け取ってAzure Stream Analyticsへ渡し、(1)Power BIでリアルタイム可視化する処理(Data in Motionの処理フロー)、(2)Azure Stream AnalyticsからデータをAzure Blob Storageにいったん格納して、Hiveによる分析や、Azure Machine Learningによる機械学習を加えた結果をPower BIで可視化する処理(Data at Restの処理フロー)が同一プラットフォーム上で行われる。

Cortana Intelligent Solution Templatesの構成図
Azure上では、Hadoopエコシステムのソフトウェアが従量課金で利用できる。「Azure Stream Analyticsの代わりにSpark Streamingを使ったり、ニューヨークの地下鉄の例のようにKafkaを挟んで処理フローを分岐したりすることも可能だ」(佐藤氏)





