
こんにちは、北瀬公彦です。6月28~30日の3日間、「Hadoop Summit 2016 San Jose」が米San Joseのサンノゼマッケンナリー会議センターで開催されました。Hadoop Summitは歴史のあるイベントで、San Joseでの開催はこれで9回目です。今回は私も含めて、初参加の人が多かったようですが、皆勤賞というツワモノも何人かいました。年々参加者が増えており、今年はおよそ4000人が参加したようです。
Hadoop Summitというブランドが付いていますが、セッション内容は、クラウド、機械学習、ストリーミング処理、NoSQLなど多岐にわたっていました。初日の基調講演は、最初にHortonworksのプレジデントであるHerb Cunitzが挨拶し、その後のMCを務めるという形で進行しました。
キーワードは「Connected Data Platform」と「Modern Data Application」
基調講演でHortonworksのCEO、Rob Beardenは、今後あらゆるビジネスにおいてデータが重要であり、「Data at Rest」(保存されたデータ)と「Data in Motion」(流れているデータ)をシームレスに利活用する基盤が「Connected Data Platform」であると説明しました。そして、このConnected Data Platformが「Modern Data Applications」には重要だと強調しました。
今回のSummitは、Connected Data PlatformとModern Data Applicationの2つのキーワードについて、事例、テクノロジ、エコシステムの観点から説明するという構成が取られていたようです。
“Data at Rest”とは、アーカイブ目的などで従来からあるようなRDMS、Hadoopクラスタに保存されるデータを指し、主にバッチ処理でデータを利用します。一方、“Data in Motion”とは、すぐに移動できて使用可能な状態にあるデータを指し、リアルタイム処理でデータを利用します。この2つのタイプのデータをいかにうまく利活用するかが、これからのアプリケーションやサービスにとって重要になります。また、この2つのデータは、クラウドとオンプレミスで収集、蓄積、分析されるので、クラウドとオンプレミスのプラットフォームをまたいだシームレスな環境も必要になるでしょう。

Hortonworks CEOのRob Bearden
Microsoftの存在感がすごかった!
今回のSummitを通じて印象深かったのは、クラウド関連のセッションが多かったことです。その中でも特にMicrosoftのプレゼンスが非常に高かった。「Microsoft Azure HDInsight」は、HortonworksのHadoop/Sparkディストリビューション「Hortonworks Data Platform(HDP)」ベースになっているので当然そうなると思いますが、それにしてもかなりの露出でした。
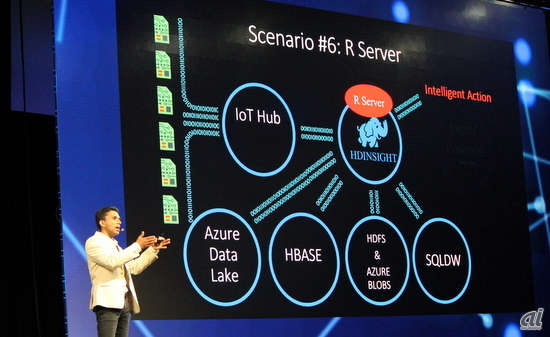
初日の基調講演では、MicrosoftのCorporate Vice President of the Data group、Joseph Sirosh氏が、事例とシナリオ例を交えながらHDInsightをはじめとしたMicrosoftのビッグデータソリューションを説明していました。若干R Server推しだったような気がします。
さらに、MicrosoftのHDInsight Group Manager、Asad Khan氏が、全米の飛行場における飛行機の発着データを、Jupyterで分析するデモを交えながらHDInsightを紹介しました。Hortonworks的には、HDP 2.5で追加予定の「Apache Zeppelin」を推しているのか、一緒に登壇していたHortonowkrsのArun Murthyの表情は少し微妙な感じでした(笑)
JupyterやZeppelinは、データサイエンティストがよく利用するPython、Scala、Rのような言語をインタラクティブに実行できるウェブベースのIDEのようなソフトウェアです。今回のSummitでは、Zeppelin関連のセッションがたくさんありました。
MicrosoftのCorporate Vice President of the Data group、Joseph Sirosh氏
Microsoftだけではありません。2日目のジェネラルセッションでは、GoogleのProduct ManagerであるJames Malone氏から、2016年初めにリリースしたHadoop/Sparkのマネージドサービス「Google Cloud Dataproc」を使って、ビッグデータをどれだけ高いパフォーマンスで処理できるかのデモンストレーションがありました。今年に入り、AWS、Microsoft、Google、IBMと、大手クラウド事業者によるHadoop/Sparkのマネージドサービスが出揃ったなという感じです。

Google Product Manager James Malone氏
また、3日目のジェネラルセッションでは、Hortonworks Senior Director of EngineeringのRam Venkateshが、AWS上にETL Cluster、Analytics Cluster、BI Clusterといったさまざまなクラスタを簡単にプロビジョニングするデモを披露し、Hortonworks Cloudのテックプレビューを紹介しました。これについて3日目の夕方にあったCloud/AutomationのBOFに参加して話を聞いたのですが、このHortonworks CloudはCloudbreak(AWSやOpenStack環境にHadoopクラスタをプロビジョニングするオーケストレーションソフトウェア)を利用しているとのことでした。

Hortonworks Cloudで、AWS上にさまざまなHadoopクラスタをプロビジョニング





