Confluent Japanは11月28日、最新レポート「アジア太平洋地域におけるデータストリーミングの活用状況」に関する記者説明会を開催した。併せて、9月に米国オースティンで開催されたグローバルイベント「Current 2024」で発表された製品とサービスのアップデートについても紹介した。

Confluent Japan カントリー・マネージャーの石井晃一氏
Confluentは、リアルタイムデータストリーミングプラットフォームを提供する米国企業。「Apache Kafka」の共同開発者によって2014年に設立され、リアルタイムデータをストリーミング、接続、処理、管理するためのソリューションを提供している。Confluent Japan カントリー・マネージャーの石井晃一氏によると、同社のグローバルビジネスは年間10億ドル(約1500億円)のランレートに達しているという。
28日に発表されたレポートでは、企業がデータストリーミングを活用することで、イノベーションの創出、AI導入の加速、ビジネスの柔軟性向上、顧客体験の強化、データアクセスや管理の課題克服にどのように貢献しているかを分析している。オーストラリア、インド、インドネシア、日本、シンガポールを含むアジアパシフィック地域のITリーダー/上級職1424人を対象に実施された。日本からは251人が回答した。
石井氏は、その中から日本に関する5つの主な調査結果を紹介した。まず、80%の組織がデータストリーミングへの投資で2~5倍の投資対効果(ROI)を得ており、13%の組織は10倍以上のROIを報告している。また、90%が2024年におけるIT投資の戦略的または重要な優先事項としてデータストリーミングを挙げている。
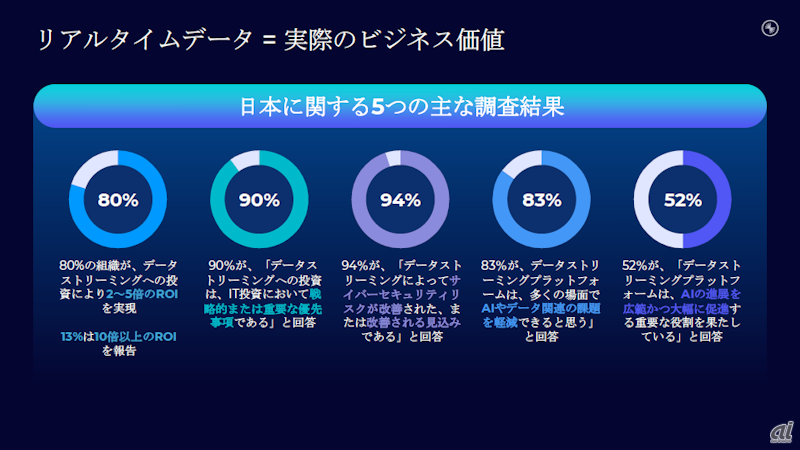
日本に関する5つの主な調査結果
94%の回答者がデータストリーミングによってサイバーセキュリティリスクが改善された、または改善されると見込んでおり、83%がデータストリーミングプラットフォームがAIやデータ関連の課題を多くの場面で軽減できると考えている。一方で、データストリーミングプラットフォームがAIの進展を大幅に促進する重要な役割を果たしていると回答したのは52%にとどまった。
「日本企業のデータストリーミングへのアプローチの特徴としては、慎重な検討と戦略的な実装が挙げられる。アジア太平洋地域(APAC)の他国と比較すると、日本企業での導入率は低いものの、品質と戦略的な導入に重点を置いていることが明らかになった」と石井氏は調査結果を振り返る。
続いて、Confluent Japan シニア ソリューション エンジニアの清水亮夫氏が、Current 2024で発表された製品/サービスのアップデートについて説明した。
まず、同氏によると、Confluentのデータストリーミングプラットフォームは、「Stream」「Connect」「Process」「Govern」の4つの主要機能で構成されているという。

Confluentのデータストリーミングプラットフォームを構成する4つの主要機能
Streamの領域では、フルマネージドサービス「Confluent Cloud」とセルフマネージドソフトウェア「Confluent Platform」を提供する。Confluent Cloudは、Kafkaをクラウド向けに再設計したもので、Amazon Web Services(AWS)、Google Cloud、Microsoftの「Azure」などのパブリッククラウドで利用できる。Confluent Platformは、Kafkaのエンタープライズ向けディストリビューションで、オンプレミスやパブリッククラウドで動作する自己管理型のソフトウェアになる。
9月には、BYOC(Bring Your Own Cloud)ベンダーのWarpStreamを買収した。これにより、フルマネージドとセルフマネージドの中間に位置するサービスの提供が可能になる、と清水氏は話す。例えば、WarpStreamのBYOCモデルでは、コントロールプレーンはConfluentが管理し、データプレーンは顧客が管理することで、顧客は自分たちのクラウド環境をコントロールしながら、運用負担を軽減することができるという。サービス提供は2025年以降を予定している。

Confluent Japan シニア ソリューション エンジニアの清水亮夫氏
Connectについては、既存のシステムやアプリからデータを容易に接続する70以上のフルマネージド型コネクターが提供されているという。「Confluent Hub」には200以上のコネクターが用意されているという。
最新のアップデートでは、ユーザーが独自のカスタムコネクターを作成してConfluent Cloudにアップロードし、使用することができるようになった。コネクターのインフラを管理することなく、特定のニーズに合わせたデータストリーミング環境の構築が可能になる。
Processのステップは、常時稼働するストリームミング処理でデータの再利用を促進するものになる。最新のアップデートでは、Confluent Cloudで「Apache Flink」の提供を開始した。Flinkはストリームプロセッシングのデファクトスタンダードであり、これを使うことでデータストリームのフィルタリング、結合、リッチ化が容易に行えるようになる。
「クラウドネイティブのサーバーレスサービスであるため、インフラ管理の手間を省き、どのような規模でも高性能で効率的なストリームプロセッシングを実現する」(清水氏)
現在、AWS、Google Cloud、Azureで利用可能だが、対応リージョンは順次拡大中とのこと。日本については、2025年1~3月期にAWSの東京リージョンで展開予定という。
「(Flinkは)生成されたデータをリアルタイムに処理でき、データが生成された場所に近いところで処理することで再利用性が向上する。一方で、分散型システムのため、セルフマネージドでは運用が複雑になるが、フルマネージドサービスだとすぐ利用でき運用負荷もかからない。インフラ管理から完全に解放され、ビジネスへの貢献に集中できる」と清水氏は強調した。
また、ゼロスケーリングの料金体系により、インフラのプロビジョニングに基づく課金ではなく、実際に使用したリソースに対してのみ課金されるため、使用していない時はコストがゼロまでスケールダウンできる点も特徴という。
Confluent PlatformでのFlinkの提供は、最新バージョン7.7では一部の顧客に限定されているが、次期バージョン7.8では一般提供(GA)が予定されている。
最後に、Governではリアルタイムデータのガバナンスを実現するための包括的なソリューションを提供している。具体的には、信頼性の高い高品質なデータストリームをビジネスに提供する「Stream Quality」、セルフサービス型のデータディスカバリーでコラボレーションと生産性を向上させる「Stream Catalog」、複雑なデータ関係を理解してより多くのインサイトを得る「Stream Lineage」で構成されている。
データの可用性、整合性、セキュリティを確保し、企業がリアルタイムデータを効果的に活用できるように設計されているという。





