日本Hadoopユーザー会は2月8日、東京都品川区で「Hadoop Conference Japan 2016」を開催した。第6回目となる今回のイベントでは「Spark Conference Japan 2016」が初めて併催され、キーノートにはApache Sparkの主要開発者であるXin Reynold氏も登壇。2016年にリリース予定のSparkの次期バージョン「Spark 2.0」の最新情報を紹介した。今回の参加登録者数は1347人で、そのうち63%が初参加だという。この記事では、同イベントのキーノートの様子をレポートする。
Apache Hadoopは、大規模データの分散処理を行うオープソースのミドルウェア。分散ファイルシステム「Hadoop Distributed File System(HDFS)」、Hadoop上の大規模データに対してMap処理(必要な情報の抽出)とReduce処理(抽出データを束ねて処理結果を出す)を行う「Hadoop MapReduce」、Hadoopクラスタの計算機リソースを管理するためのミドルウェア「Hadoop YARN」の3つのコアコンポーネントと、25以上のエコシステムコンポーネントで構成される。

日本Hadoopユーザー会 会長 濱野賢一朗氏
始めに登壇した日本Hadoopユーザー会 会長 濱野賢一朗氏(NTTデータ)は、誕生から10年目を迎えたHadoopを取り巻く現在の環境について、「最近、何がHadoopなのか分からなくなってきたと言われる。これは、さまざまな周辺ソフトや分散処理エンジンが登場し、それらを組み合わせた商用ディストリビューションが出てきたためだ。Hadoopの形が1つではなくなってきた」と説明した。
ディストリビューションの選択によってコンポーネントの組み合わせが異なるために、ユーザーから見えるHadoopの全体像が多様化している。これは、過去にLinuxディストリビューションも同じような状況だったが、今は収れんされて、どのディストリビューションも同じような組み合わせに落ち着いた。Hadoopディストリビューションもいつかは収れんされていくが、今は過渡期なのだと濱野氏は言う。「正直、今はHadoopを選定するのが難しい時期と言える」(濱野氏)
YARNは機械学習言語をサポートしていく
続いて、Hadoopコミッター(Hadoopのソースコードを変更する権限を有する開発者)である小沢健史氏(NTT)と鰺坂明氏(NTTデータ)が登壇した。

Hadoopコミッターの小沢健史氏(右)と鰺坂明氏(左)
YARNの開発者である小沢氏は、同コンポーネントの進化の方向性について、「現在のYARNは並列処理分散処理ミドルウェアを管理対象としてCPU、メモリ、ディスクを中心とした処理に焦点を当てているが、今後はGPGPUやFPGAを含む計算リソースを扱えるようなデータセンターOSに進化していく」と述べた。
その背景には、機械学習に特化した高水準言語「Apache SystemML」や「Google TensorFlow」、「Microsoft Project Catapult」などの登場がある。SystemMLやTensorFlowは、高速に機械学習を実行するためにGPUを利用する。また、Microsoft Project Catapultは、FPGAを用いてスループットを上げる仕様になっている。YARNは、これらの新しいミドルウェアやフレームワークを含めて管理できる方向に開発を進めていくとする。
また鰺坂氏は、HDFSの進化について「この1~2年の間に、セキュリティと運用性が大幅に向上した。例えば、アクセス制御、データの暗号化、ローリングアップグレードなどの機能が追加されている。これにより、Hadoopが使える領域が広がった」と述べた。
鰺坂氏はHadoopの開発コミュニティの動向にも言及した。2015年の変更コード行数を集計した結果、従来からのコントリビューターであるHortonworksとClouderaの2社は引き続きコミュニティに大きく貢献していた。国内では、ヤフー、NTTデータ、NTTの貢献度が大きいのも従来通りである。2015年に注目すべき企業はHuaweiで、この1年で急激に貢献が増えている。Huaweiの2015年の変更コード行数は、Hortonworksに次いで2番目に多かった。
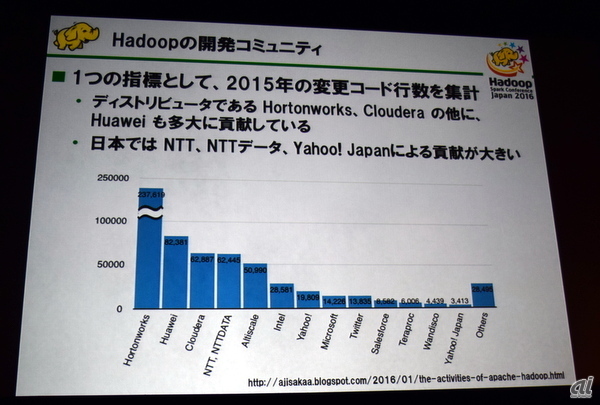
2015年のHadoop開発コミュニティの状況
次期Sparkは処理性能を10倍に
キーノートには、Sparkの主要開発者であるXin Reynold氏も登壇した。「2015年は、Sparkにとって大きな飛躍の年だった。この年、Sparkは最も活発なオープンソースプロジェクトであり、1000人以上がコントリビューターとして開発に参加した」とReynold氏。
Apache Sparkは、オープンソースの汎用データ分析処理エンジン。「Mapper」「Reducer」「JOIN」「GROUP BY」など任意の演算子でアプリケーションを書ける仕様になっているため、繰り返しの機械学習、ストリーミング、複雑なクエリ、バッチなど多様なデータ処理が可能になっている。また、それぞれの演算子が生成するデータをメモリ内に保存するため、低レイテンシの計算、効率的な反復アルゴリズムを実現している。

Spark開発者であるDatabricksのXin Reynold氏
Sparkは、RDD(ノードに分散された読み取り専用オブジェクトの集合)をコアにして、その上にSQLクエリ処理コンポーネント「Spark SQL」、ストリーム処理コンポーネント「Spark Streaming」、機械学習処理コンポーネント「Mlib」、グラフ処理コンポーネント「Graph X」などがある構成だ。Reynold氏は、これらのコンポーネントで構成されるSparkの機能を「フロントエンド」と「バックエンド」に分類して、次期バージョンSpark 2.0での進化を説明した。フロントエンドにはRDDやDataFrameなど、バックエンドにはスケジューラや演算子などが含まれる。
Spark 2.0で目指すのは、「フロントエンドAPIの整備」と「バックエンドの処理性能を10倍にする」ことだという。
フロントエンドAPIの整備では、特にDataFrame APIを機能拡張する。DataFrame APIは、プログラミング言語「R」のデータ構造であるDataFrameをモデルにしており、フィルタ、グループ化、SQLクエリに相当する集合演算を提供するもの。
現在のSparkは、バックエンドでJavaVMを用いて処理を行っており、フロントエンドのRDDからバックエンドのJavaVMにデータを引き渡すAPIを提供している。Reynold氏によれば、次期バージョンではDataFrame APIを拡張し、さまざまなソースからデータを収集してバックエンドに引き渡すようにする。また、データ処理を実行するエンジンとしてTungstenも利用できるようにする。
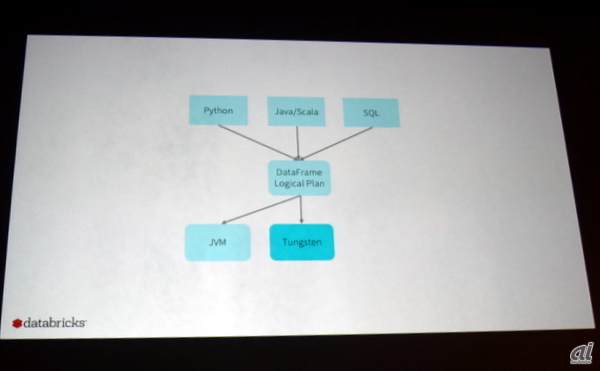
次期バージョンSpark 2.0ではDataFrame APIを拡張
Spark 2.0の正式リリースは4~5月を予定しており、現在GitHub上で急ピッチに開発が進められているという。





