今回は、私の所属するチームが準優勝した「Home Credit Default Risk」というKaggleのコンペについて話します。期間は2018年5月中旬から8月末で、つい先日行われたコンペとなるのですが、特に今回は、チームでKaggleに取り組むという点にフォーカスしていこうと思います。国際色豊かな12人のチームを組んでコンペに臨み、過去最高規模となる7198チーム(参加者数8572人)の中で2位に入賞できた裏側をこの場を借りてお伝えすることで、少しでも興味を持ってもらえれば幸いです。
チーム結成までの流れ
チームは、有志で集まったKagglerのオフ会がきっかけで結成されました。オフ会参加者はオープンに募集されていたので、勇気を出して出席したのを今でも覚えています。ほぼ全員が初対面でした。
オフ会での技術の話は、とても楽しく刺激的でした。こんな人たちと一緒にKaggleを通して学びを得られたら幸せだなと思い、チームを組んでコンペに取り組むことをその場で決意したのを覚えています。その後に、海外にいるチームメンバーの知り合いも加わり、最終的には12人の大きなチームとなりました。
取り組んだコンペの課題について
「Home Credit Default Risk」は、Home Creditという会社でローンを組んだユーザーが完済できるか/できないかの二値を予測するといった金融関係のコンペです。特徴的なのは予測に使用できるデータとして、200種類以上もの情報が与えられているという点でした。例えば、申込者の個人情報(家族構成、雇用情報、居住地や住宅情報など)やローン情報(借入金額や支払回数、種類など)をはじめ、さまざまなものがありました。データの種類が多く、予測モデルもバリエーションが豊富でした。
アプローチについて
予測精度を高めるためのアプローチは、大きく2つに分けられます。
- 予測モデルそのものの精度を高める
- 複数のモデルの予測結果を統合する
今回は、予測に使用できるデータの種類が多く、さらにチームでの取り組みであったので、(2)について深掘りします。
一つのモデルが予測した結果が、仮に70%の正答率を持っているとします。70%の正答率を持つモデルで予測を行った場合、不正解率は30%です。では、3つの独立したモデルA、B、Cが集まって予測をしたらどうなるでしょうか。多数決で最終的な予測結果を決定するとすれば、2つ以上が誤った答えを出す確率は、下図のように21.6%となります。よって正解率は78.4%です。
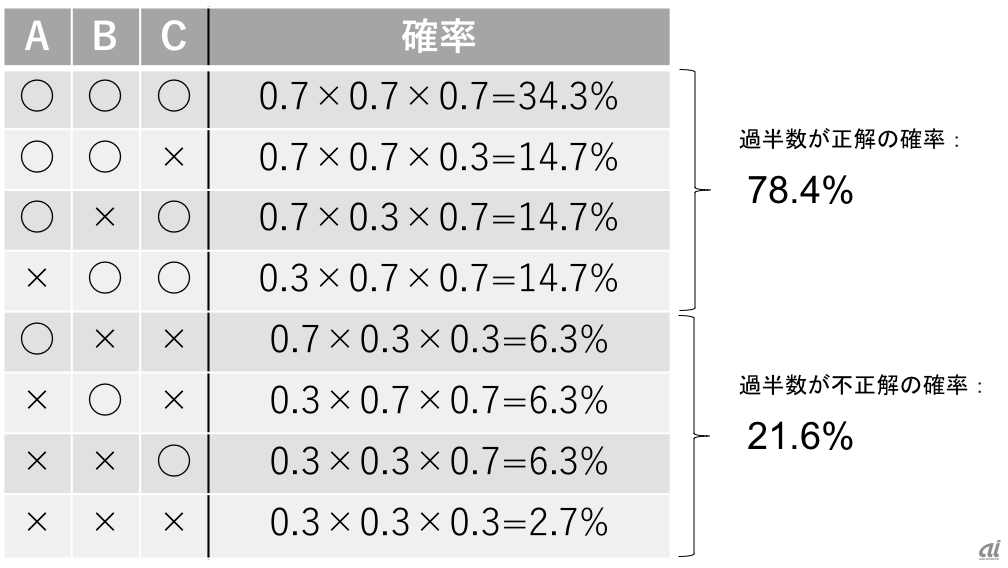
複数の予測モデル(A、B、C)の予測結果を組み合わせた場合の予測精度。一つ一つのモデルは70%の精度しか持たないにも関わらず、3つの予測結果を組み合わせると78.4%の精度が出ている。
70%の精度しか持たないモデルからでも、複数を併せることによって80%近くの精度を持つ予測ができるのが分かります。これが、複数のモデルを組み合わせることによるメリットの直感的な理解です。
ではモデルを適当に作りまくれば精度が上がるのかというと、そう単純ではありません。各々のモデルが類似してしまう状況を防ぐ必要があります。例えば、AもBもCもとても似ていて、同じような結果ばかりを出すとしましょう。すると、本質的には一つのモデルで予測をしているのと変わりなく、複数モデルの結果を統合するメリットが薄れてしまいます。「3人寄れば文殊の知恵」とは言いますが、3人とも同じことばかり考えていては嬉しくありません。予測モデル同士の「多様性」が重要になるのです。





