Kagglerの個性
ここで、チームで取り組むことの価値が出てきます。実際にKaggleに取り組んでみると分かるのですが、一人ひとりのKagglerは個性を持っており、得意とする手法やアプローチは千差万別です。それらの個性を集約することで、最終的な予測モデルに多様性が生まれてくるのです。
Kagglerの個性といってもイメージが湧きにくいと思うので、少し具体例を挙げてみようと思います。
Kaggleで扱う予測問題に取り組む手法は、大きく二種類に分類できると思っています。ニューラルネットワークを用いるものと、勾配ブースティングと呼ばれる手法を用いるものです。両者は性質が大きく異なり、それらの中にも細分化された数多くのアルゴリズムが存在しています。どんなアルゴリズムを選ぶかというのも、Kagglerによりさまざまです。
また、モデルに入力する特徴量の多様性も、最終的な予測精度の多様性にとって重要です。モデルの性質上、どうしてもモデル内では表現しづらい特徴というのは存在します。例えば、ニューラルネットワークも勾配ブースティングもモデル内部で特徴量同士の乗除演算を表現できないため、入力の特徴量の掛け算や割り算の結果を人間が作成して入力するというのは重要となります。このような、モデルが表現できない部分を人間が抽出する作業は、「特徴量エンジニアリング」と呼ばれています。
ここが機械学習の精度を突き詰める上で個性の生まれやすいところで、「どういった人がローンを完済できなくなってしまうのだろうか」などと考えつつ、与えられたデータとにらめっこしながら一人ひとりが特徴量エンジニアリングを行っていくのです。具体例としては、「年収が高かったとしても家族の人数が多いと家計を支えるのも大変だろうから、(年収)÷(家族人数)を特徴として入力してみよう」や「現職で働いている時間の割合が人生の中で長い人ほど安定していそうだから、(現職の雇用期間)÷(年齢)を特徴として入力してみよう」といったようなものが挙げられます。ここの発想や思考は、やはり千差万別です。
また、単純に掛けたり割ったりするだけでなく、特徴抽出を高度なアルゴリズムを用いて行ったりもします。例えば下図は、提供された特徴量を、UMAPと呼ばれるアルゴリズムを使って無理やり二次元上に可視化した図です。小さな点がいくつも分布していますが、この点の一つ一つが、ローンの申込情報に対応しています。見てみると一様に分布しておらず、いくつもの島を作って分布していることが分かるかと思います。この島の一つ一つが何か似た特性を持ったローン申し込みの集合となっています。直感的には理解が難しいものですが、このような情報も特徴量として有益なものとなります。
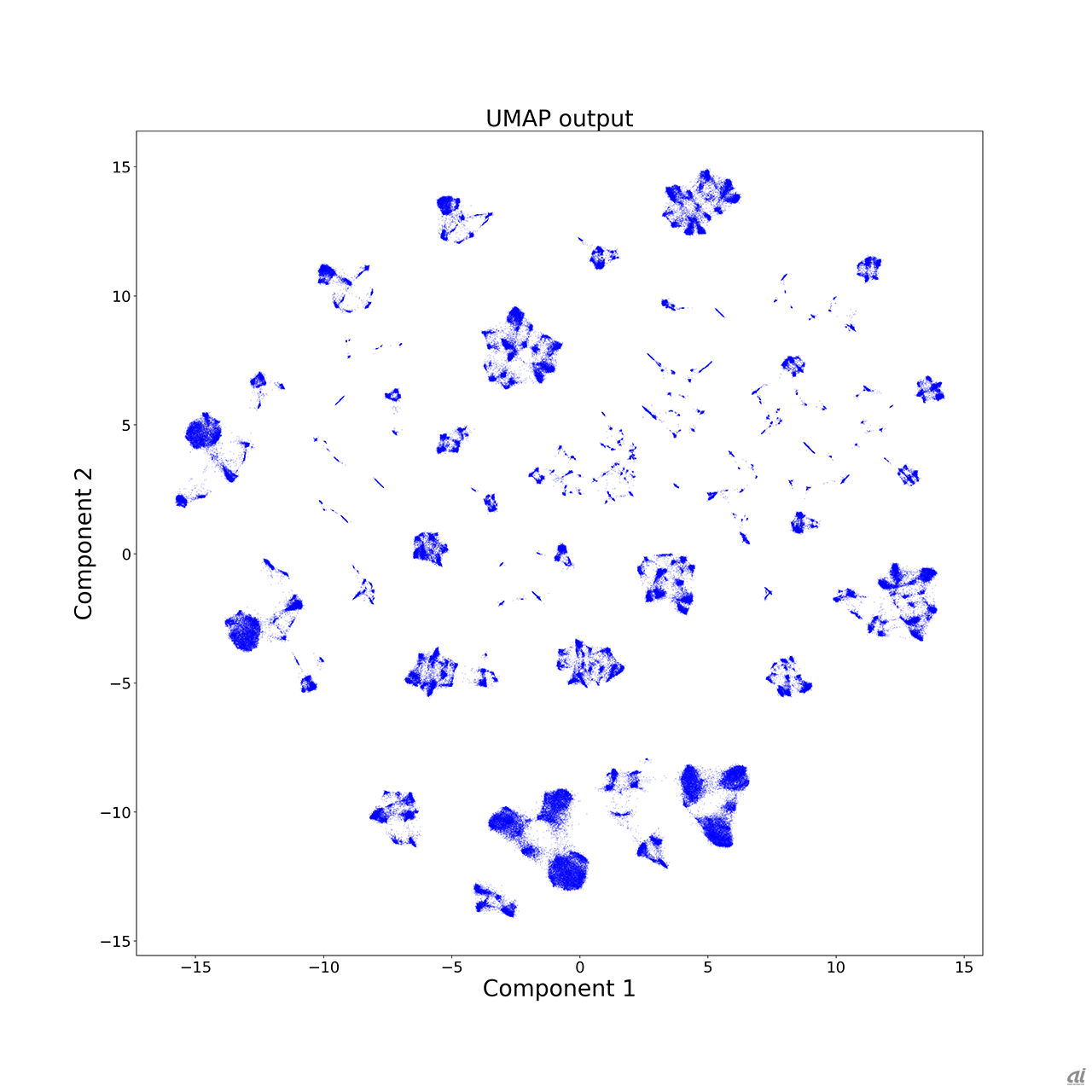
UMAPというアルゴリズムにより二次元上に投影された、ローン申込みの情報。一つ一つの点が、ローン申し込みの情報に対応している。
他にも、手法は星の数ほど存在します。このように、特徴抽出の方法一つとっても、何をどのように使うかに個性が現れてくるのです。
そして、前述でも述べたように個性ある複数の予測モデルを組み合わせることが精度を上げる重要なポイントです。今回、私たちのチームでは一人ひとりのメンバーが、アイデアを共有し合いながらも他メンバーのアイデアに完全に浸ることなく個性を発揮できたことが、上位入賞の要因の一つだったと感じています。





