NVIDIAとMicrosoftは、巨大な自然言語生成モデル「Megatron-Turing Natural Language Generation(MT-NLG)」を共同で開発した。両社によれば、このモデルは「これまでにトレーニングされた中で、最も強力な単体のトランスフォーマー言語モデル」だという。
提供:Microsoft
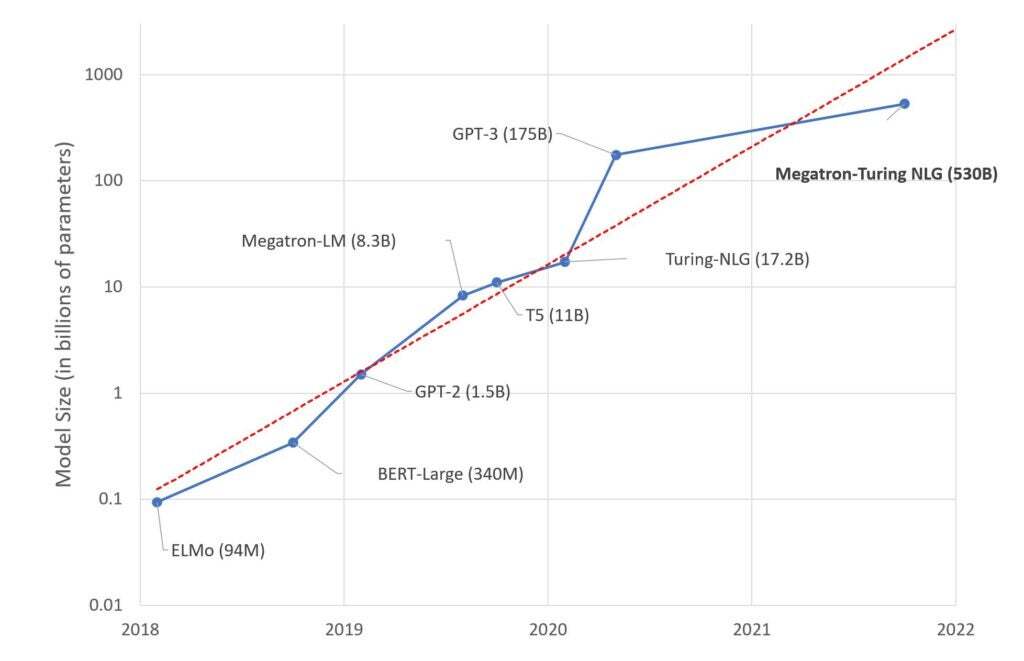
この言語モデルは105層で、5300億のパラメーターを持ち、実行するにはNVIDIAの「Selene」のような、大規模なスーパーコンピューターハードウェアを必要とする。
有名な言語モデル「GPT-3」のパラメーター数は1750億だった。
このモデルは、3390億のトークンを含む15のデータセットでトレーニングされたもので、大規模なモデルでも少ないトレーニング量でうまく動作することを証明した。
ただし、現実世界の言語やサンプルを使って学習する必要があるという点は変わらず、このモデルも、AIが古くから抱えている問題からは逃れられていない。それはバイアスの問題だ。
両社は、「大規模な言語モデルは、言語生成の最新技術を進歩させ続けているが、やはりバイアスや問題のあるデータなどの問題を抱えている」と述べている。
「MT-NLGでは、モデルがトレーニングに使用されたデータから偏見やバイアスを拾ってしまっていることが分かった。MicrosoftとNVIDIAは、この問題の解決に向けて取り組んでいる」(両社)
Microsoftのチャットボット「Tay」が、インターネット上の対話による学習によって、ものの数時間で差別発言をするようになったという問題が起こったのは、それほど前のことではない。
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。