NTTと早稲田大学は6月16日、誤った正規表現の文字列抽出を検出して自動的に修正する技術を世界で初めて実現したと発表した。同17~22日に開催される「PLDI2023」で詳細を報告するという。
今回開発した技術は、多様なバリエーションを扱うことからあいまいさのない正確な記述が求められる正規表現の文字列抽出において、誤った記述を検出し自動的に修正する。NTTは、正規表現によるパターンの確認を実施するプログラムの振る舞いとして、「ECMAScript 2023」に完全準拠した正規表現エンジンの振る舞いを理論モデルとして厳密に定義し、この理論モデルに従って修正結果となる正規表現に誤りがないことを保証する条件を生成する方法を提案した。
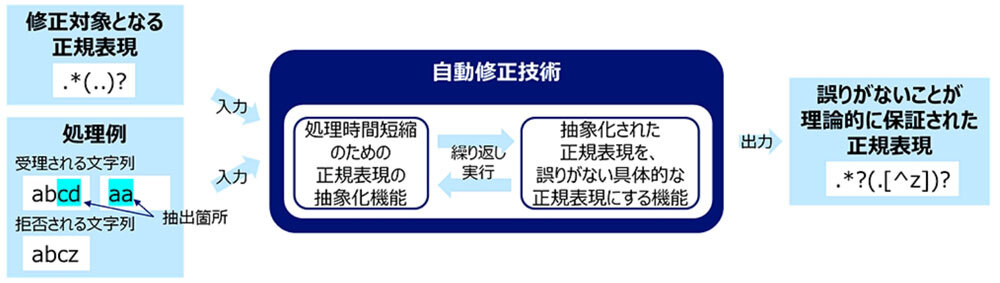
今回開発した技術のイメージ(出典:NTT)
さらに、条件を生成する方法を活用して、修正対象となる正規表現と利用者が希望する規表現に対するポジティブな例(受理される文字列)とネガティブな例(拒否される文字列)を与え、処理時間を短縮するために正規表現を抽象化する機能と、抽象化された正規表現を誤りのない具体的な正規表現にする機能を交互に繰り返して実行することで、誤りがないことが理論的に保証された正規表現を出力するアルゴリズムを考案した。早稲田大学理工学術院の寺内多智弘教授がこの手法の理論的な正確さを検証した。
NTTによると、パターンに合致する文字列をチェックする正規表現の誤りを自動で修正する技術はあるものの、文字列チェックに比べて膨大なバリエーションを扱う文字列抽出の正規表現の誤りについては極めて高度な専門知識を必要とすることから、機械的に修正する仕組みが難しかった。文字列抽出の正規表現の誤りは、情報漏えいなどのセキュリティ問題やサービス停止など原因になることが多い。
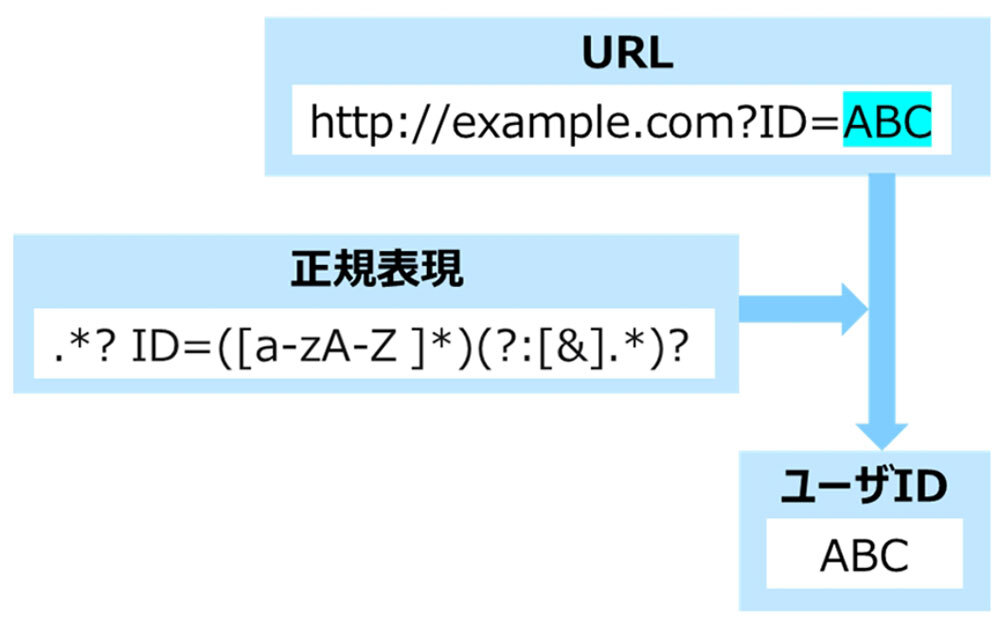
正規表現を用いた文字列抽出の例。"ID="の後で末尾または"&"の前にあるアルファベット大文字または小文字から成る文字列を抽出する(出典:NTT)
NTTは、今回の技術を活用することで、高度な専門知識や経験を持たない開発者でもソフトウェアの安全性を向上させることが可能になるほか、非熟練者がAIを用いて作成したプログラムの安全性を確保する効果も期待できるとしている。





