日本テラデータは10月11日、ビッグデータ分析アプライアンス「Teradata Aster MapReduce Appliance」の販売を開始した。最小構成の税別価格は4130万円から。同日から出荷している。
Aster MapReduce Applianceは、リレーショナルデータベース(RDB)とMapReduce技術を統合した並列処理型ソフトウェアの「Aster」をハードウェアにインストールした、ビッグデータを分析するためのアプライアンス。今回は英語版で販売、出荷する。2013年のはじめには日本語対応版を予定している。
Asterは、Teradataが2011年3月に買収した非構造化データを分析するためのソフトウェア。年内に日本国内で提供することが表明されていた。今回のAster MapReduce Applianceには、「SQL-MapReduce」と「SQL-H」という機能を搭載している。
SQL-MapReduceは、ウェブサイトのアクセスログやテキストデータ、マシンやセンサのログデータといった“多構造化データ”(一般的には非構造化データ)を分析する際に、高頻度で利用される50以上のMapReduce処理を関数として事前にパッケージ化、分析するユーザーがSQLの関数として呼び出せる機能だ。多構造化データに対する並列分析処理を、SQL記述とほぼ同等のスキルで対話的、反復的に実行できるとメリットを説明している。
基本的にSQLの文法で記述されるSQL-MapReduceだが、開発者がJavaで記述することも可能だ。Aster内に配備されるMapReduce関数をSQL文の中で呼び出し、実行することで処理される。代表的な関数は、シーケンシャルな物事の順序や経路を分析するためのnPath関数、順序に基づいて番号を付与していくSessionize関数、文章などのデータをキーワードに分解するTokenize関数などだ。
SQL-Hは、Hadoop分散ファイルシステム(Hadoop Distributed File System:HDFS)に対して、SQLとSQL-MapReduceを利用してアクセスするための機能になる。Hadoopの環境では、データはファイルとして管理され、ファイルはデータブロックごとに分解されて各コンピュータノードに分散して格納される。
SQL-Hでは、Hadoop同様にオープンソースソフトウェア(OSS)で提供される「HCatalog」が提供するHDFS内ファイルのデータ定義情報を読み取る。そのためAsterからは、テーブルとカラム(列)を指定するのと同じ方法でHDFS管理下のデータにアクセスして、SQLかSQL-MapReduceで実行できる。SQL-Hを活用すれば、Asterの並列処理の性能を最大限に生かすことができ、構造化データと多構造化データの両方を扱うことが可能だ。
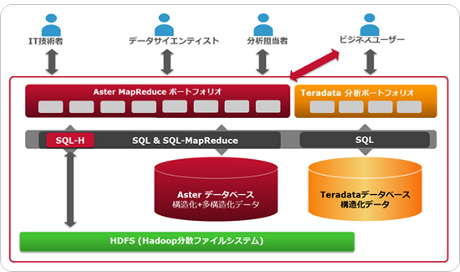
Asterの位置付け
これまで、RDBへのアクセスにはSQLが用いられ、データ操作に特化したSQLという平易な言語で分析担当者は、データを分析してきた。一方でRDBに格納されるデータは、あらかじめ定義された行と列のテーブル形式に構造化する必要があった。このため、ウェブサイトのアクセスログやテキスト、マシンやセンサのログといった多構造化データの処理には不向きとされていた。
現在OSSで提供されるHadoopは、多構造化データの並列処理フレームワークとしてMapReduceを提供しているが、MapReduceはJavaなどの開発言語を利用する必要があり、データ分析にはソフトウェア開発者と同等のスキルなどが必要と指摘されている。SQL-MapReduceは、こうしたSQLとMapReduceの双方の利点を含んだ技術と説明。多構造化データを容易に分析できるとメリットを打ち出している。
ログに代表される多構造化データは、さまざまな社会事象やビジネスプロセスの詳細な記録であり、データ量は大規模なものとなる。本来、このようなデータを分析する意義は、その中に隠されているパターンや異常事態を探し出すことにあり、そのためには何度も条件を変更しながら、対話的に分析できる環境が求められると指摘する。Asterは、分析ユーザーがアクセスできる分析の範囲を拡大させるとともに、分析の速度と効率を改善できる技術と説明している。
今回はアプライアンスとして提供されるが、ソフトウェア単体で提供することを現在検討している。





