
HBase登場の背景
2月24日、オープンソースソフトウェア(OSS)プロジェクト支援団体Apache Software Foundation (ASF) は「Apache HBase 1.0」のリリースを発表しました。HBaseの開発が開始されてから約8年、数々の機能強化と安定性向上のための改良を経て、成熟した製品として一つのマイルストーンに達したことが合意された結果です。第2回では、このHBaseについて掘り下げていきます。
HBaseは、ASFのプロジェクトとして開発されているOSSのNoSQLデータベースです。同じくApacheプロジェクトの分散データ処理基盤として開発されている「Apache Hadoop」上で動作し、分散型のスケーラブルなデータストア機能を提供しています。
HadoopやHBaseは、Googleの大規模分散処理基盤を構成する技術をもとに、オープンソースコミュニティがクローンとして開発したソフトウェアです。価格性能比の高いコモディティサーバを利用して信頼性の高い大規模なシステムを構築するというGoogleの思想は、そのままこれらのプロジェクトに引き継がれています。
Hadoopは、分散ファイルシステム「Google File System (GFS) 」とアプリケーション実行フレームワーク「MapReduce」をオープンソースで実現するためのプロジェクトですが、対象としていたのは主に非構造化データに対するバッチ処理でした。これに対してHBaseは、構造化されたデータに低レイテンシでアクセスするために設計されたデータストアである「BigTable」のオープンソース実装です。
初期のBigTableの利用例のひとつに、ウェブアクセス解析のシステムがあります。このシステムでは、無数にあるウェブサーバから大量かつ高頻度のデータが投入される一方で、短時間での集計と統計情報の低レイテンシでの取り出しをサポートする必要がありました。このような要件を満たすための設計が最適化され、それはHBaseの使い方を考える上で重要なポイントになります。
HBaseのデータモデルと実装
HBaseそのものを紹介する前に、HBaseで扱われるデータモデルについて説明します。HBaseのデータモデルはBigTableが元になっていますので、BigTableの論文の次の非常に簡潔な説明を引用します。「BigTableは“スパース”で分散され、永続性のある、多次元ソートマップである」。そして「各“マップ”はソートされた行キー、カラムキー、タイムスタンプでインデックスされ、値は解釈されていないバイト列」と続きます。
マップという用語を聞き慣れない方がいるかもしれませんが、マップとは、重複しないキーを使って構成される、キーと値のペアの集合のことを指しています。HBaseでは、行キー、列(カラム)キー、タイムスタンプという多次元の要素からなるキーと、そこから一意に定まる値のペアがデータ構造を表現します。
ここで、データを2次元の表の形式で表してみましょう。このHBaseのテーブルは、リレーショナルデータベース(RDBMS)のテーブルと同様に垂直方向に行、水平方向にカラムが並び、各行は1つの行キーと任意の数のカラムを持ちます。上で述べた多次元マップは、キーが指定するテーブル内の特定セルに格納される値、という形で表現することが可能です。シリーズ第1回でHBaseはワイドカラムストア型に分類されていましたが、これはマップの追加により各行に任意の数のカラムを保持できることを示しています。
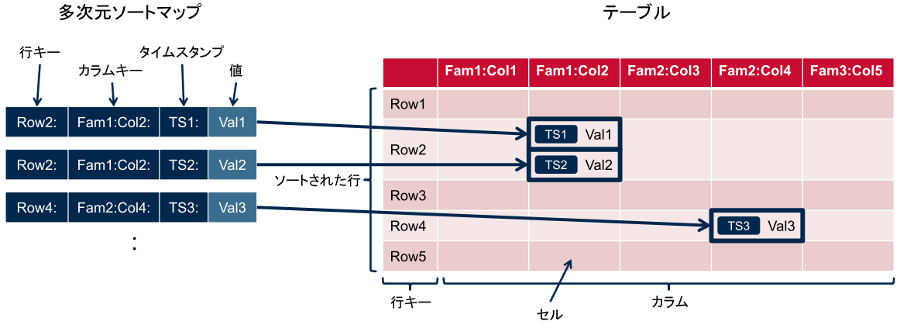
図1:多次元ソートマップをテーブルとして表現(筆者作成)
これをRDBMSのリレーショナルモデルと比較してみると、その違いが際立ちます。リレーショナルモデルにおけるリレーションは、多次元の属性を持つ“タプル(値の組、テーブルの行で表現される)”の集合ですが、リレーション間の演算を成り立たせるためにリレーションのすべてのタプルは同じ属性を持ち、重複やNULL値を許容しません。さらに、データの矛盾を排除するために積極的に正規化されます。





