SAPジャパンは11月5日、オープンソースソフトウェア(OSS)の分散並列処理プログラミングフレームワーク「Apache Hadoop」にあるデータの分析を効率化できるというインメモリクエリエンジン「SAP HANA Vora」の提供を開始した。モノのインターネット(Internet of Things:IoT)の活用や分析も効率化できるとメリットを説明している。
HANA Voraは、OSSのデータ処理フレームワーク「Apache Spark」を拡張して活用。Hadoop内にあるデータなどさまざまソースからの情報と、インメモリデータベース「SAP HANA」で管理されたトランザクションデータを透過的に活用できるという。
SAPのインメモリコンピューティングを分散データにまで拡張し、オンライン分析処理(OLAP)と似たような分析が可能と説明。Hadoop分散ファイルシステム(Hadoop Distributed File System:HDFS)のデータをドリルダウンで分析できると言う。ビジネス活動をコンテキストに沿って完全に把握できるようになり、意思決定を支援できるとしている。
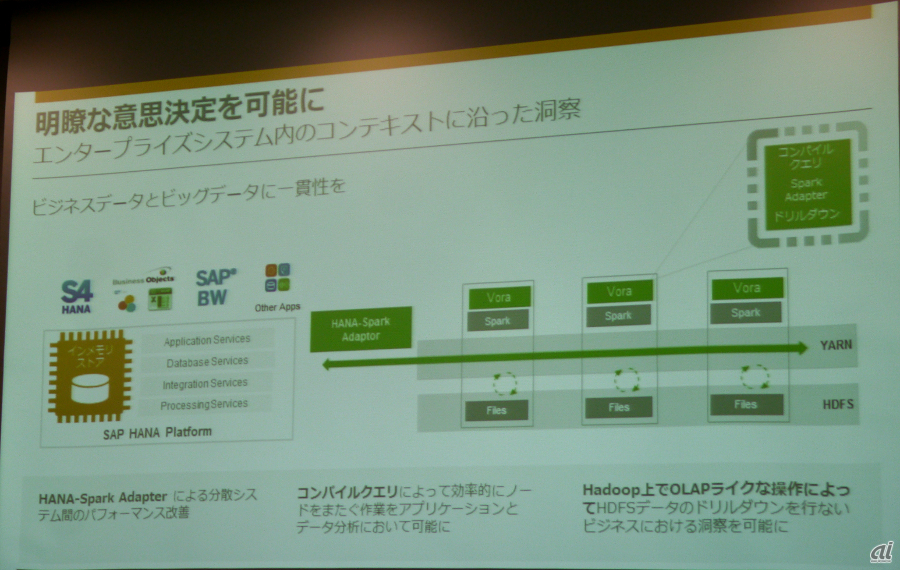
HDFSにあるデータをドリルダウンで分析できるという
統計向けプログラミング言語「R」を対象にしたAPI「Spark R」とSparkに含まれる機械学習ライブラリ「MLlib」の後継である「Spark ML」もサポートしており、データサイエンティストや開発者が慣れている環境を利用しながら、容易にデータにアクセスできるようになっている。このことから企業データとHadoopデータをマッシュアップが可能になり、未知の質問に対する答えを探せると説明。ScalaやPython、C、C++、R、Javaといった言語をサポートしていることから、それらに対応した各種ツールの選択肢も提供できるとしている。
HANA Voraは単体で活用でき、あらゆるHadoopクラスタに対応。SAPのアジア太平洋地域シニアディレクターのRohit Nagarajan氏は、「これまでのHadoopへの投資コストを生かしながら、インメモリコンピューティング環境での活用が可能になる」としている。

SAP アジア太平洋地域 シニアディレクター Rohit Nagarajan氏
Nagarajan氏は「現在のデジタル化はハイパーコネクティビティ、スーパーコンピューティング、クラウドコンピューティング、スマートワールド、サイバーセキュリティという5つのメガトレンドによって実現されている。あらゆる企業が業務改革を迫られており、それに対応できない企業は、競争力を落とし、成長できない」と企業を取り巻く現況を解説した。
「だが、その一方で、企業が収集した膨大なデータをどう利活用していくのか、ビジネス上の意思決定にどうつなげるのか、ビックデータを管理するための膨大なコストをどう解決するのかといったことが課題となっている。そうした課題を解決するのがHANA Voraであり、ビッグデータの世界とエンタープライズの世界の隔たりをなくすものになる」と位置付けた。
Nagarajan氏はまた「先進的なインメモリ環境における活用が最大の特徴である。これまでは、ビジネス上の意思決定をする際に分散化されたデータを統合するのに複雑な作業が必要だった。HANA Voraでは、分散システム間のパフォーマンスを改善し、コンパイルクエリのサポートにより、ノードをまたぐ作業を効率化できる。ビジネスデータとビッグデータを一貫性を持った形で扱うことができ、それをもとにした洞察が可能になる」と解説した。

SAPジャパン バイスプレジデント プラットフォーム事業本部長 鈴木正敏氏
SAPジャパン バイスプレジデント プラットフォーム事業本部長の鈴木正敏氏は、「HANA Voraによって、業務システムとビッグデータ、データレイクをシームレスに接続することで、ビッグデータが単なるバズワードでなく、実際に経営者の意思決定の高度化に貢献するためのものになる」とメリットを説明した。
「HANA Voraは、すべてのHadoopディストリビューションベンダーと連携することが可能であり、Hadoopを利用している顧客にHANA Voraの価値を届けることができる。また、HANAパートナーとの連携により、HANAを活用している顧客に対しても、Hadoopとの連携による価値を提供できる」(鈴木氏)
金融サービス、電気通信、医療、製造、ハイテク分野などでの活用を見込んでおり、金融取引データや顧客履歴データから新たな異常を検出するといった使い方が可能と説明。トラフィックパターンを分析することで、ネットワークのボトルネックを回避できるという。部品表やサービス記録、センサデータをまとめて分析することで、予防保全を実現し、製品のリコールプロセスを改善するといった活用が可能になる。
鈴木氏は、「ビッグデータはあらゆる企業でその利用が模索されているものであり、業種を問わずに提案をしていきたい」とした。





