富士通研究所は4月16日、新たなディープラーニングによる物体検出技術を開発したと発表した。この技術は、少数のデータしか学習に使用できない場合でもディープラーニングによる物体検出を可能とする人工知能(AI)技術で、医療画像からの組織検出精度を2倍以上向上させることができるという。
新技術の適用イメージ(出典:富士通研究所)
同研究所は、この技術を富士通のAIサービス「Zinraiプラットフォームサービス」 での学習モデル構築技術として、2018年度中に導入することを目指す。
医療分野でのAI活用では、診療画像の分析に、異常箇所などの物体検出を自動化する取り組みが進む。この取り組みでは、ディープラーニングを用いるのが一般的であるものの、高い精度を得るためには、学習させるための数万枚規模の正解データ付き画像が必要とされる。しかし現状では、正解データは専門知識を持つ医師しか作成できないため、大量入手が困難という課題があった。
正解データ付き画像を増やすためには、大量の画像に対してニューラルネットワークを用いて物体位置を推定させることで正解データを補う方法が考えられる。しかし、従来技術では、少量の正解データで学習したニューラルネットワークに、実際の物体位置と正確に一致する場所を推定させることが困難となり、不正確な推定によるデータが学習に加わることで、ますます精度が劣化してしまう。

画像復元により推定位置を検証する新しいネットワーク構造(出典:富士通研究所)
そこで同研究所は、検出用ニューラルネットワークの推定結果を手掛かりに、元の画像を復元させる復元用ニューラルネットワークを利用し、出力された推定位置がどの程度正しいかを検証する技術を開発した。間違った推定位置から復元された画像は、元画像と一致しないため、2つの画像を比較することで、推定位置の正しさを検証できる。推定と復元を大量の画像に対して繰り返し行い、正解データを増やすことで、正確な推定位置が出力される状態に近づけることができる。
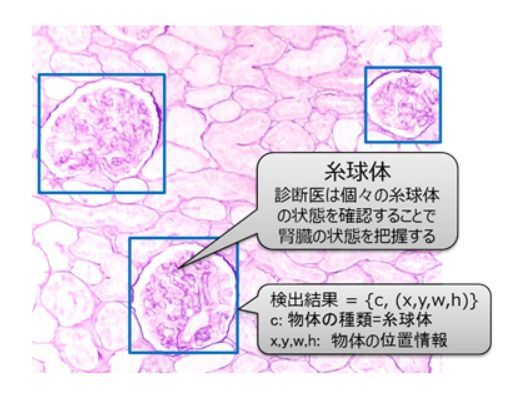
今回開発された技術は、京都大学大学院医学研究科との共同研究での成果で、腎生検画像からの糸球体の検出に適用した。正解データ付き画像50枚のみを用いて学習した従来のニューラルネットワークでの物体検出と、正解データのない画像450枚を活用した新技術での物体検出を比較をしたところ、人間と同等である見逃し率10%以下という条件下で、従来の2倍以上である27%の精度を達成した。
同研究所では今後、今回行った糸球体検出を応用し、腎臓の定量的な評価手法の実現に向けた研究に取り組む予定。また、同技術を正解データ付き画像の少ない分野での物体検出に広く応用させていく。応用例では、製造ラインの画像を使った異物の検出、インフラ設備の各種センサーによる診断画像からの異常個所の発見、建築図面からの使用部材のリストアップなどが考えられるという。





