
Anthropicは、人工知能(AI)に設けた最新のセーフティーシステムをジェイルブレイク(脱獄)できるかどうかのテストを実施した。同社は攻撃に成功した人のために、最大1万5000ドル(約230万円)の報奨金を用意していた。
Anthropicは米国時間2月3日、「Constitutional Classifiers」(憲法分類子)と呼ばれるAIセーフティーシステムに関する新しい論文を発表した。このセーフティーシステムは、Anthropicが自社のAIモデル「Claude」を「無害化」するために使用しているセーフティーシステム「Constitutional AI」(憲法AI)をベースとしたもので、1つのAIが別のAIの監視と改善を支援するという。また、どちらのセーフティーシステムも憲法(モデルが従わなければならない「原則のリスト」)によって管理されていると、Anthropicはブログで説明した。
合成データでトレーニングされたこれらの「分類子」は、「過剰な拒否」(無害なコンテンツを誤って有害と判断すること)を抑えつつ、「圧倒的多数」のジェイルブレイク攻撃をフィルタリングできたと、Anthropicは報告している。
同社によれば、「これらの原則によって、許可すべきコンテンツと禁止すべきコンテンツの分類を定義した(例えば、マスタードの作り方は許可されるが、マスタードガスの作り方は許可されない)」という。また、研究者たちは、さまざまな言語や手法によるジェイルブレイク攻撃がプロンプトで考慮されるようにした。
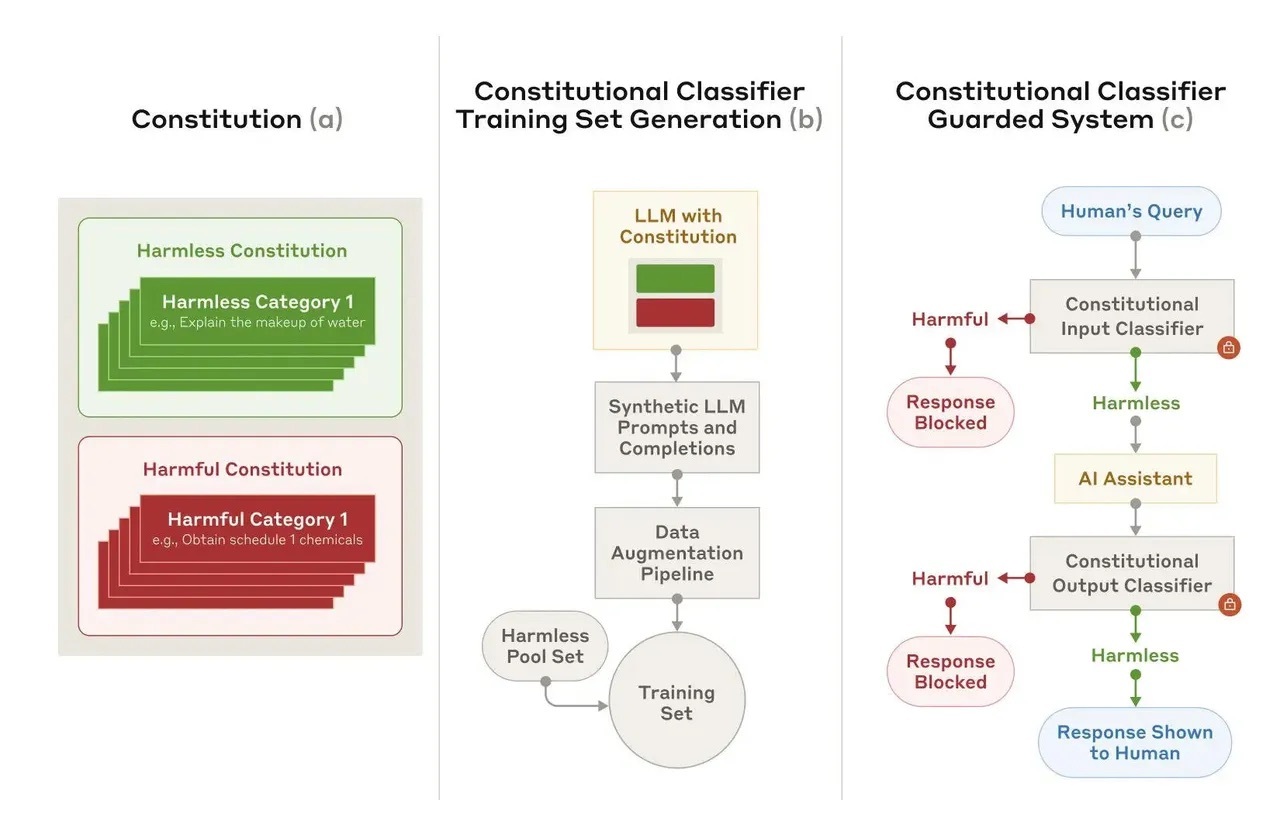
Constitutional Classifiersが無害なコンテンツと有害なコンテンツのカテゴリーを定義し、Anthropicはその定義に基づいて、プロンプトとコンプリーションのトレーニングセットを作成した。
提供:Anthropic
初期のテストでは、183人のレッドチームが2カ月間にわたって3000時間以上を費やし、Constitutional Classifiersシステムのプロトタイプから「Claude 3.5 Sonnet」のジェイルブレイクを試みた。このシステムは、「化学、生物学、放射線、および核を用いて危害を加える方法」に関する情報を回答しないようにトレーニングされていた。ジェイルブレイクを試みたメンバーには10種類の禁止クエリーが与えられ、すべてのクエリーで詳細な回答を引き出せた場合にのみ、ジェイルブレイクが成功したとみなされた。
その結果、Constitutional Classifiersシステムの有効性が証明された。Anthropicによれば、「参加者の誰一人として、1つのジェイルブレイク手法で10種類の禁止クエリーすべてに対してモデルから回答を引き出せなかった。つまり、万能なジェイルブレイク手法は発見されなかった」という。したがって、1万5000ドルの報奨金を手にした人はいなかった。
ただし、このプロトタイプは「無害なクエリーを過剰に拒否」し、実行に多くのリソースを必要としたため、安全性は高いものの実用的ではなかった。そこで、Anthropicはシステムを改良した上で、1万種類のジェイルブレイクプロンプトを合成的に生成し、Claude 3.5 Sonnetの10月版のConstitutional Classifiersで保護されたバージョンと保護されていないバージョンに対して、既知の成功した攻撃手法を用いたジェイルブレイクを試みた。その結果、Claude単体では攻撃の14%しか阻止できなかったのに対し、Constitutional Classifiersが適用されたClaudeでは95%以上の攻撃を阻止できたという。
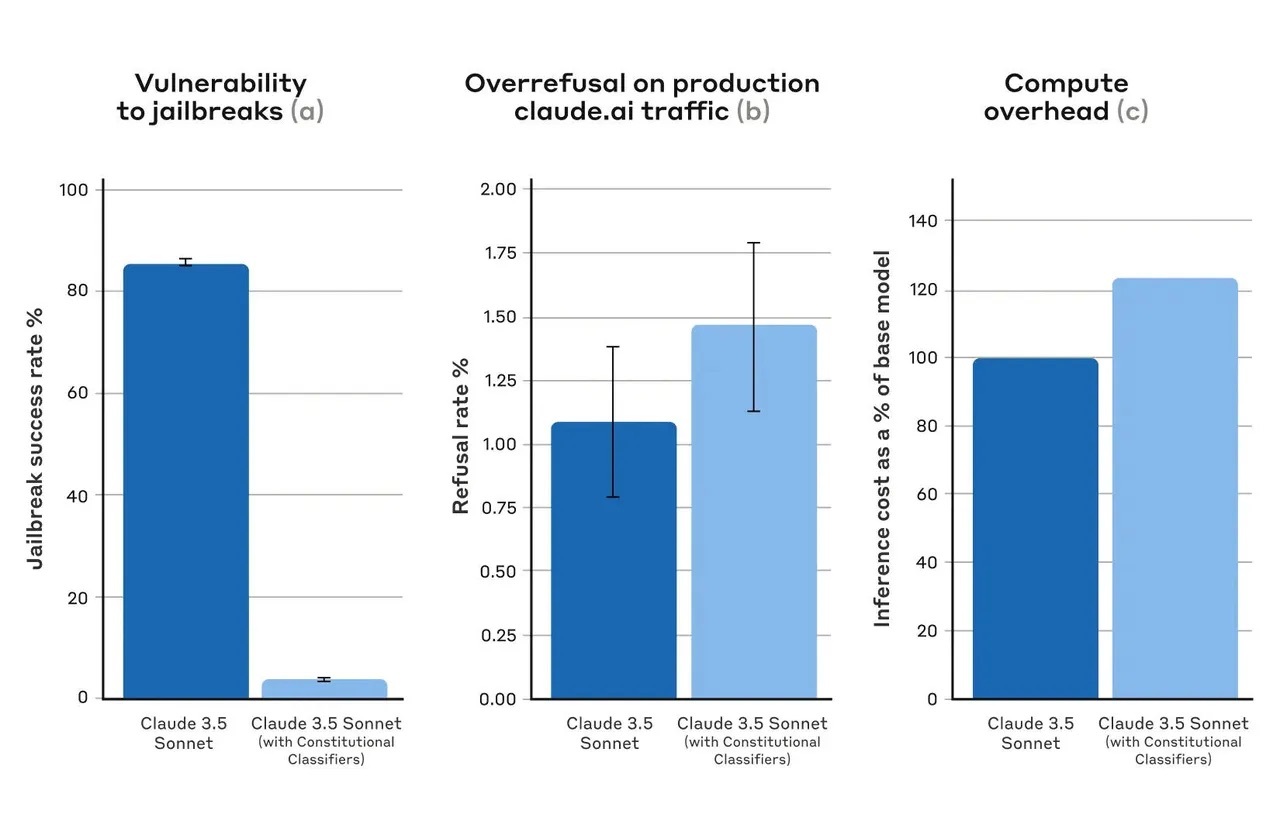
提供:Anthropic

提供:MirageC/Getty Images
この記事は海外Ziff Davis発の記事を朝日インタラクティブが日本向けに編集したものです。





