サンフランシスコで米国時間6月6〜8日にかけて開催されている「Spark Summit」では、ビッグデータ分野に参入している多くの企業がオープンソースのインメモリ指向ビッグデータプラットフォーム「Apache Spark」関連の発表を行う予定だ。
先陣を切ってMapRとMicrosoftがそれぞれ、新たなSparkディストリビューションを発表した。いずれも、スタンドアロンのSparkクラスタをベースにするのではなく、Hadoopをベースにしているものの、いずれのディストリビューションもSparkを旗印に掲げ、Sparkを中心に据えたかたちで作り上げられている。
Microsoftは複数のSpark関連製品を発表
MicrosoftのSparkディストリビューション「Spark for Azure HDInsight」は、既にプレビュー版が利用可能となっていたが、6日付けで一般提供が開始された。最初のプレビュー版はほぼ1年前に発表されており、「Windows」向けの「HDInsight」(同社のクラウドをベースにしたHadoopディストリビューション)をベースにしていたが、同社はそのディストリビューションを軸にして、Linux向けのディストリビューションを再設計した。なお、Spark for Azure HDInsightには、PythonやScalaで記述されたコードを処理できるカーネルとともに、「Jupyter」というデータ科学者向けのラボノート(実験ノート)環境が同梱されている。Azureアカウントを所有しているのであれば、クラスタを用意し、リンクをクリックして複数の入門用ノートに目を通すことで、簡単かつ迅速にSparkを用いた作業を開始できるようになる。
この他にも同社は、「Microsoft Power BI」とSparkの統合(「Spark Streaming」との統合を含む)や、「Microsoft R Server for HDInsight」とオンプレミス環境に対応した「Microsoft R Server for Hadoop」についても発表した。
Sparkを前面に押し出すMapR
MapRはオープンソースのApache Sparkを利用しているものの、同社独自のHadoopディストリビューションや、そのクローズドソースの固有コンポーネント(HDFSと互換性のある「Map-FS」や、「Apache HBase」と互換性のある「MapR-DB」、「Apache Kafka」とAPIレベルで互換性のある「MapR Streams」を含む)との統合を注意深く進めてきている。
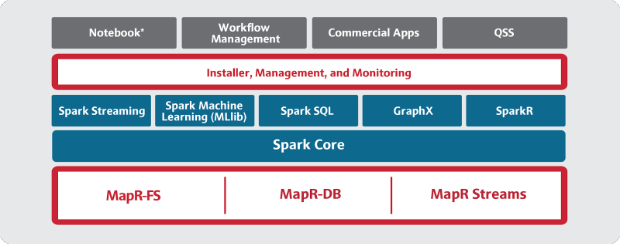
提供:MapR
(MapReduce経由ではなく)Sparkに直接向かう道
MapRのJack Norris氏は筆者に対して、同社の訓練教材を利用する多くの顧客は、Hadoopの基礎を最初に学ぶのではなく、Sparkから入る道を選んでいると語った。また、Microsoftのある従業員は筆者に対して、HadoopネイティブなMapReduceはほとんど死に体(これは筆者の言葉であり、同従業員が用いた表現ではない)であるため、Sparkがさまざまな点で新たな標準になっていると語った。
Sparkを前面に押し出すというパラダイムは、現時点のビッグデータ分野において相対的に優位となっている。筆者はこれが正しいかどうか、確信を持てずにいる。特に「Apache Tez」によってポストMapReduceと称するべき高機能なプラットフォームが提供され、「Apache Hive」やTezといった既存のHadoopエコシステムのコンポーネントがサポートされ続けることを考えると、確かなことは何も言えないと感じている。しかし、一定数以上の顧客がSparkを中心に据えたディストリビューションを望むようになれば、ベンダーはその要求に応える必要が出てくることになるだろう。
置き換えではなく、同化吸収へ
いずれにしても、MapRとMicrosoftの両社とも新たなディストリビューションで最近一般的になりつつあるコンフィギュレーション、すなわちHadoop(つまりYARNやHDFS)上でSparkを稼働させ、しばしばKafkaも利用するというコンフィギュレーションを支持している。このため両社とも、顧客のニーズに応じてHadoopスタックの他のコンポーネント(Hiveや「Apache Pig」、HBase)を利用できるようにしている。
この記事は海外CBS Interactive発の記事を朝日インタラクティブが日本向けに編集したものです。





