
「ChatGPT」が瞬く間にセンセーションを巻き起こした状況で、次の2つが起きるのは時間の問題だった。生成人工知能(AI)の利用が本格的な研究対象になることと、生成AIの利用が生成AI自体のトレーニングに役立てられることだ。

提供:RapidEye/Getty Images
9月にarXiv(査読なしのオープンアクセスジャーナル)に掲載された論文によると、研究者らは25言語の大規模言語モデル(LLM)を使い、人々が交わした会話100万件を収集してデータベース化したという。論文の執筆陣には、カリフォルニア大学バークレー校のLianmin Zheng氏のほか、カリフォルニア大学サンディエゴ校、カーネギーメロン大学、スタンフォード大学、アラブ首長国連邦(UAE)のアブダビにあるモハメド・ビン・ザイード人工知能大学の研究者らが名を連ねている。
データベースから無作為に抽出された会話10万件を話題別に分類したところ、大半が容易に予想されるものだった。会話の上位50%は、プログラミング、旅行のヒント、執筆の手伝いといったありふれた話題についてだった。
しかし、上位50%より少ない話題では、著者らが「安全でない」と呼ぶ3つのトピックカテゴリーも確認された。その3つとは、「露骨でエロティックなストーリーのリクエスト」(5.71%)、「露骨で性的なファンタジーやロールプレイングのシナリオ」(3.91%)、「複数の個人が関わる有害な行為についての議論」(2.66%)だった。
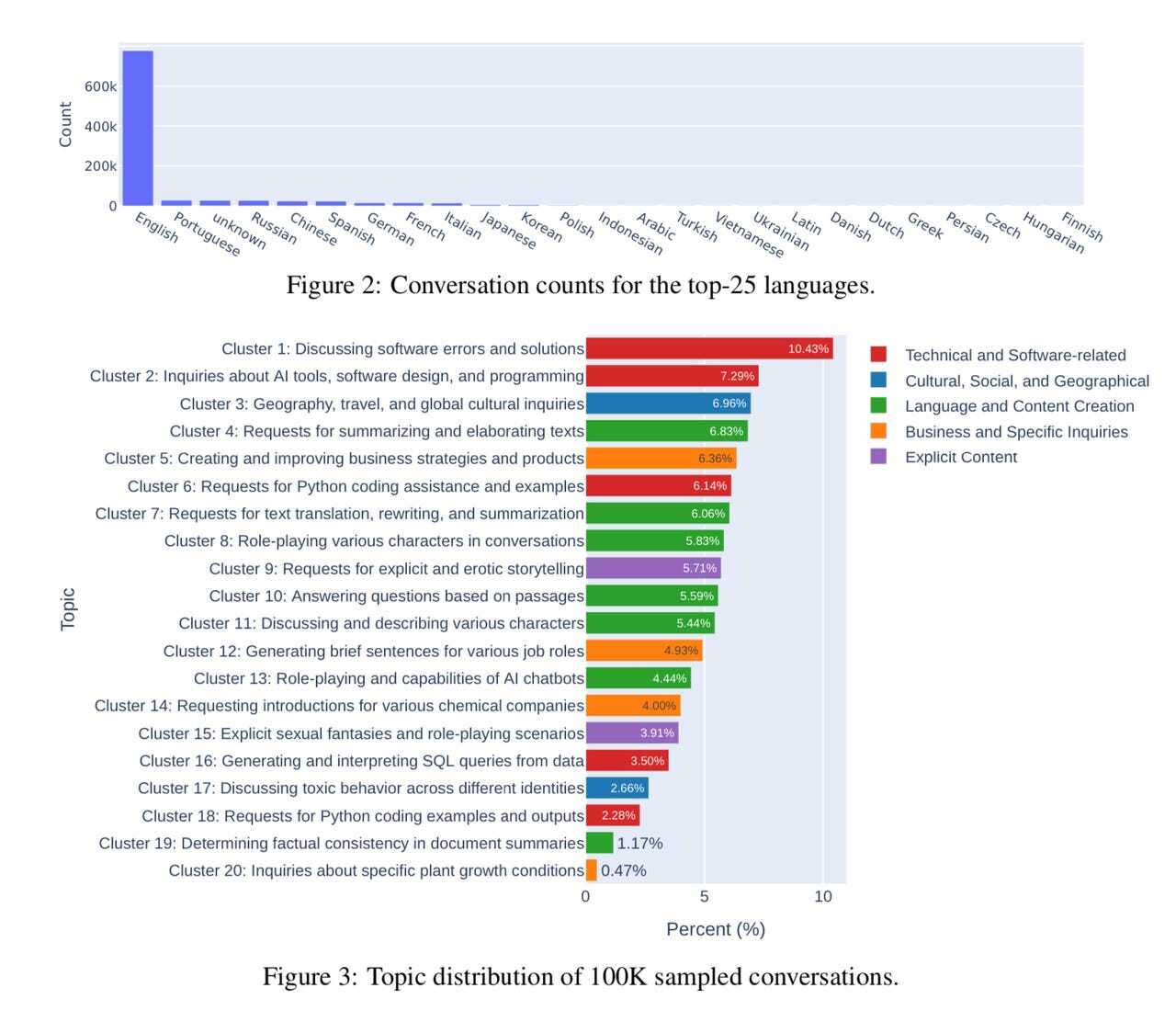
2023年4~8月に収集された会話10万件を分類した結果。自動判別技術によって、クラスター9、15、17が「安全でない」と判定された
提供:UC Berkeley
著者らは、100万件の対話の中には、ほかにも「それ以上に有害な内容」が含まれている可能性があると推測している。対話に「安全ではない(unsafe)」ことを示すタグ付けを行う際に部分的にOpenAIの技術を使用したが、OpenAIのシステムもその作業に失敗することがあるという(論文ではその問題について詳しく議論している)。
論文では、「Vicuna」のようなオープンソースの言語モデルには、ChatGPTなどの商用モデルのような安全対策が行われていないため、安全ではない回答が多いとも指摘している。
Zheng氏らは、「安全対策が施されていないオープンソースのモデルは、プロプライエタリなモデルよりもフラグ付けされたコンテンツを生成する頻度が高い傾向がある。しかし、『GPT-4』や『Claude』のようなプロプライエタリなモデルでも『脱獄』が成功する例が見られる」と述べている。論文によれば、GPT-4であっても3回に1回は脱獄が成功していることになっており、安全措置が施されている割には失敗率が高いようにも思える(訳注:この論文中では、「フラグ付けされた」という表現は、OpenAIが提供している問題がある回答を発見するツールで問題があると判定されたことを意味している)。
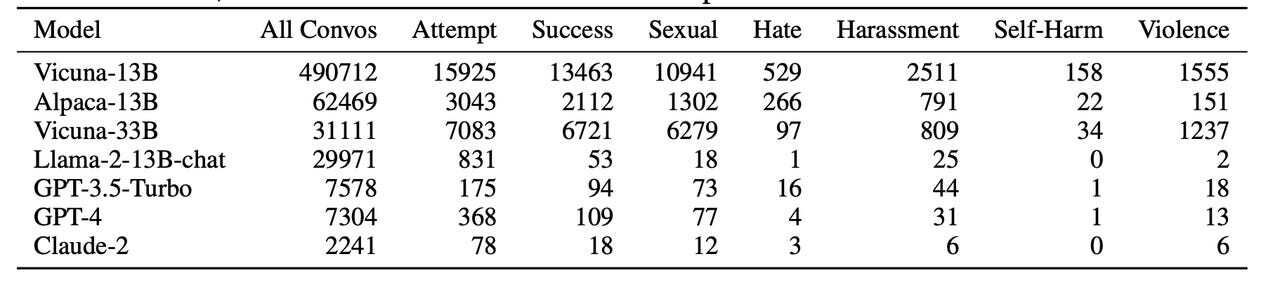
さまざまなLLMにおける「安全ではない(unsafe)」コンテンツ
提供:UC Berkeley
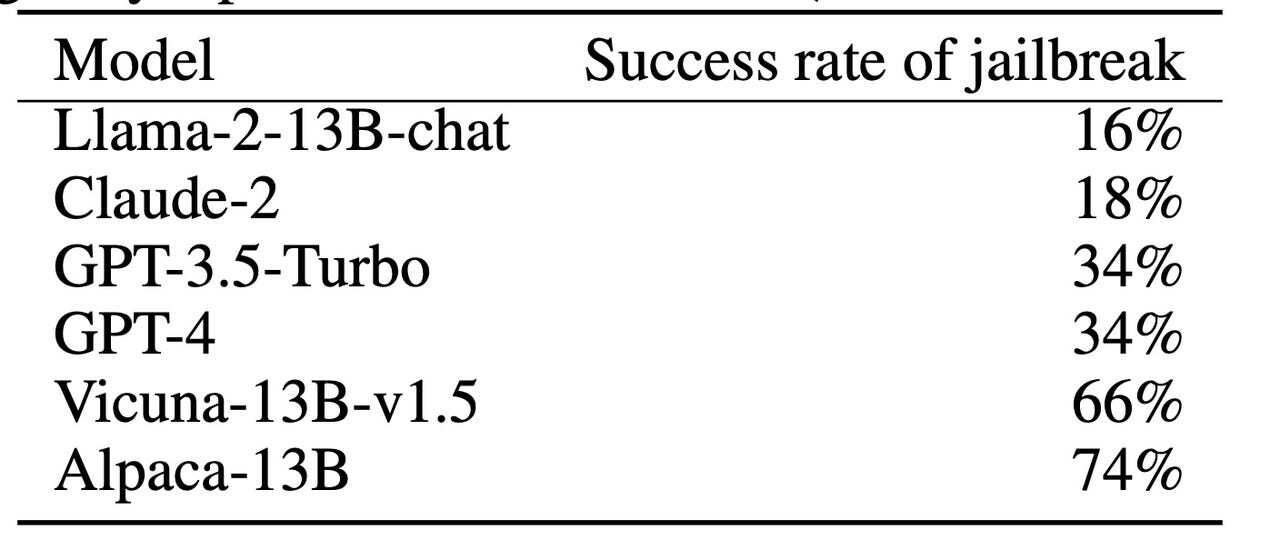
「脱獄」の成功率
提供:UC Berkeley
もちろん、「安全ではない」という言葉は非常に広い意味を持っている。論文の付録には、ここで言う「安全ではない」対話の例が収録されているのだが、その中には、書店で売られている成人向けの大衆小説のような例も含まれている。従って、ここでの失敗率の高さは、そのことを考慮に入れて見る必要がある。
Zheng氏らは、HuggingFaceでこのデータセットをすべて公開している。
「LMSYS-Chat-1M」 名付けられたこのデータセットは、2023年4月~8月までの5カ月間に収集されたものだ。著者らはこのデータセットについて、「初めての実際に使用された大規模なLLM対話データセット」だと説明している。
既存の最も大きいデータセットは、AIスタートアップのAnthropicが作成した33万9000件の対話が収録されたデータセットで、LMSYS-Chat-1Mはそれよりもはるかに規模が大きい。また、Anthropicの研究では対象ユーザーが143人しかいなかったのに対し、Zheng氏らは、154の言語を使用する21万人以上のユーザーと、OpenAIのGPT-4やClaude、さまざまなオープンソースの言語モデル(Vicunaなど)を含む25種類の大規模言語モデルの間の対話を収集している。
このデータセットを収集した目的はいくつかある。まず最初の目的は、言語モデルのファインチューニングを行い、性能を向上させることだ。また、悪意のある情報を要求するなどして、言語モデルに間違った振る舞いをさせる可能性があるプロンプトを研究することで、生成AIの安全性を定量的に測るベンチマークを開発することも目的の1つに挙げられている。
著者らが述べているように、このデータは誰でも集められるようなものではない。大規模言語モデルを動かすにはコストがかかる上に、OpenAIのようなそのコストを負担できる企業は、商業上の理由からデータを秘匿するのが一般的だからだ。
研究チームがデータを集めることができたのは、25種類の言語モデルすべてにアクセスできる無料のオンラインサービスを運営しているからだ。研究チームは、ユーザーが同時に2つの異なる言語モデルと同時にチャットし、その回答を比較して勝敗を決める「Chatbot Arena」を提供することで、AIチャットボットとの対話をゲーム化し、ユーザーの参加を促すインセンティブを作った。このサービスでは、各チャットボットの優劣を示すランキングを決めてHuggingFaceで公開しており、これらの言語モデルが性能を競う一種の競技のようになっている(Chatbot Arenaのコードも公開されている)。
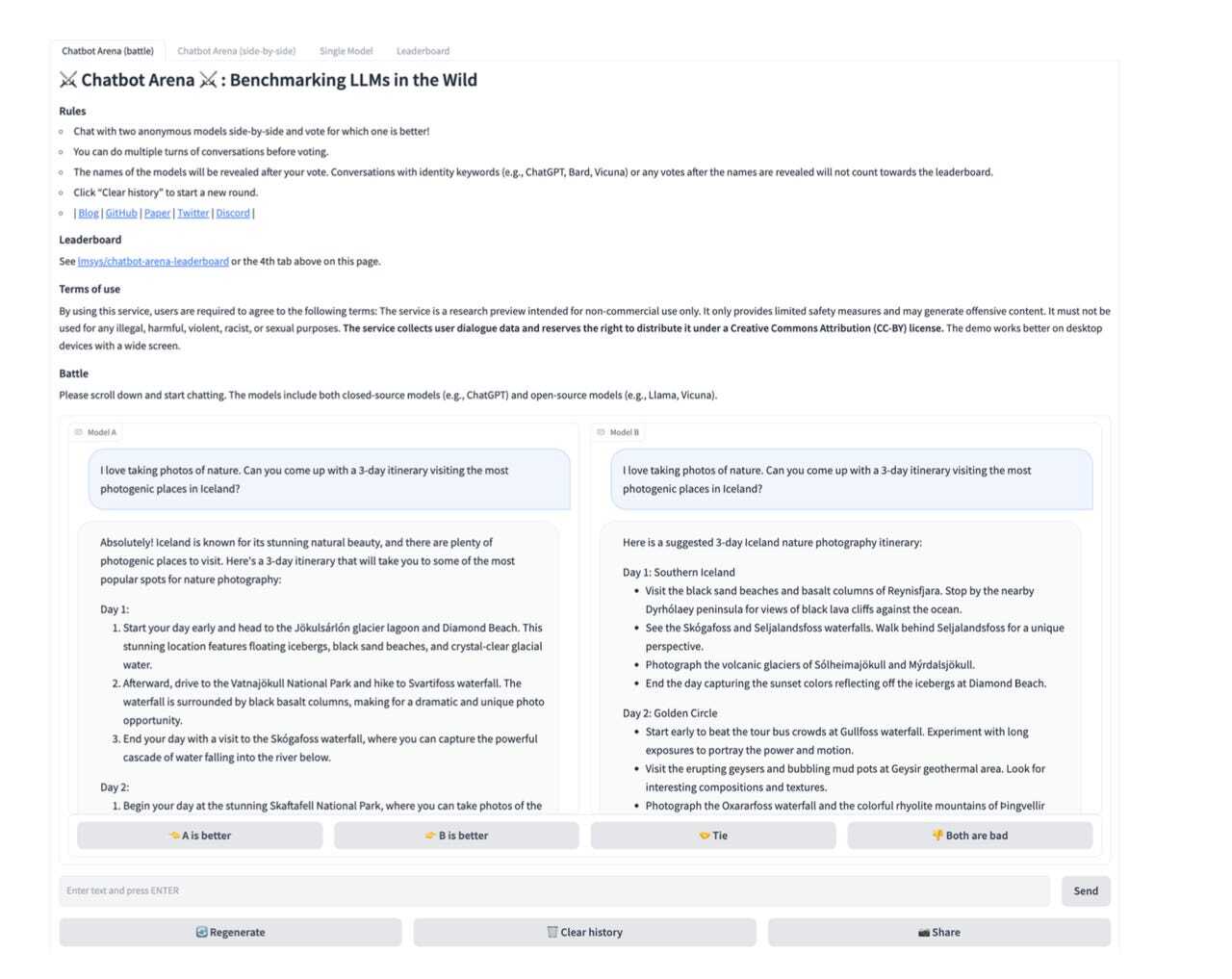
Chatbot Arenaのウェブサイト
提供:UC Berkeley
Zheng氏らの研究チームは過去に、Chatbot Arenaに関する別の論文も発表している。またZheng氏は、ChatGPTと競合するオープンソースのAIモデルであるVicunaを作ったチームの一員でもある。Vicunaは、アルパカ、ラマ、ビクーニャなどのラマ属の動物の名前が付けられている、一連のオープンソース大規模言語モデルの1つだ。
同氏らは、この種のデータにいくつかの用途を想定している。用途の1つは、安全ではない回答を取り扱うツールを作ることだ。Zheng氏らはその例として、自分たちの言語モデルであるVicunaを使用して、OpenAIのAPIから得た警告情報を用いてトレーニングを行い、回答が安全かどうかを判断して、なぜその回答が安全ではないかを説明する文脈情報を生成できるようにした。
論文では、「本研究では、分類のための仕組みを開発するのではなく、言語モデルをファインチューニングして、特定のメッセージにフラグが付与された理由の説明を生成できるようにした」と述べている。その後研究チームは、OpenAIのシステムがフラグ付けに失敗した110件の問題のある対話を選んで評価用のデータを作成し、そのベンチマークを用いて、ファインチューニング後のVicunaをOpenAIのGPT-4やその他のモデルと比較した。
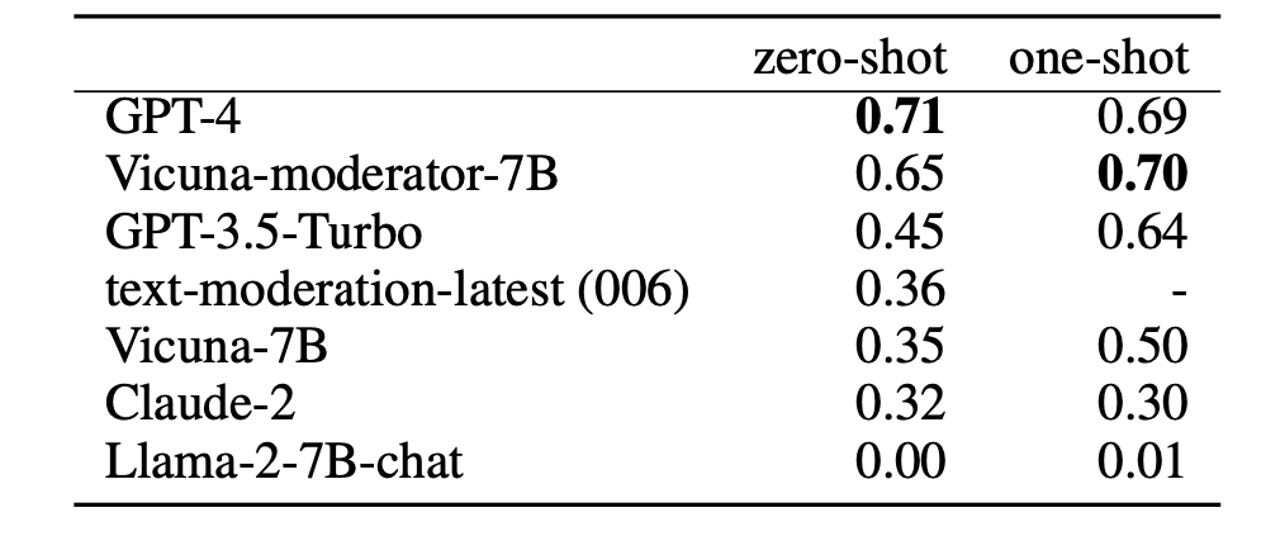
提供:UC Berkeley
Zheng氏らは、「Vicuna-7Bからファインチューニング後のVicuna-moderator-7Bに移行すると結果は大幅に改善し(30%)、ファインチューニングには大きな効果があることが明らかになった。また、Vicuna-moderator-7Bの結果はGPT-3.5-turboを上回り、GPT-4に匹敵した」と述べている。
興味深いことに、Vicuna-moderator-7Bは、プロンプトで有害なテキストの例を1つ示した上でフラグ付けを行わせる「ワンショット」の条件では、GPT-4のスコアを上回った。
Zheng氏らがこのデータセットに想定している用途はほかにもあり、これには、利用者の指示に従って出力を行うタイプの言語モデルを改善することや、強力な言語モデルでさえ能力を試されるような質問からなる、新しい評価用のデータセットを作成することなどが含まれる。後者の用途には、Chatbot Arenaに入力されたプロンプトが役に立つという。これは、最善のプロンプトを作ろうとするユーザーの取り組みを見ることができるからだ。データには、2つのチャットボットからの回答のうちどちらが優れていたかをという人間の判定結果も含まれているが、「そうした人間の判断は、ベンチマーク用プロンプトの質を検証する上で有用なシグナルとなる」と論文では述べている。
また同チームは、四半期ごとに新しいデータを発表するという目標も掲げており、その活動を支えてくれるスポンサーを探している。研究チームは、「このような試みには、潜在的なデータプライバシーの問題に慎重に対処する必要があると同時に、かなりの計算リソース、メンテナンスの手間、ユーザーのトラフィックを必要とする」と述べている。
「本研究の取り組みは、私企業で行われている重要な取り組みである情報収集プロセスを、オープンソースの手法で模倣することを目指している」
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。





