
パナソニック ホールディングス(パナソニックHD)は11月22日、階層的な画像認識を実現するマルチモーダル基盤モデルを開発したと発表した。これは、大規模言語モデル(LLM)の事前知識を活用することで、任意のテキスト入力に応じたセグメンテーション(画像中の物体を見つけ出し、画素単位で映っているものを識別すること)タスクを遂行できる基盤モデルで、カリフォルニア大学バークレー校と共同開発した。
今回開発した「HIPIE(Hierarchical Open-vocabulary Universal Image Segmentation)」は、40以上の公開データセットを対象とした評価実験において、2023年11月21日現在の世界最高性能を達成しているという。今後、車載センサーの危険検知やロボットでの操作対象の認識、ドローンの地形分析、医療画像などの階層的な画像理解が必要とされる場面で、現場でのアノテーションの負担削減が期待される。
HIPIEは、「オープンボキャブラリー(任意の言語で扱える)」「ユニバーサル(任意の画像を扱える)」「階層的(シーンに含まれる情報を階層的に捉えられる)」という特徴を備えた画期的なセグメンテーションモデル。画像に映ったシーンを詳細に理解することが可能となり、モビリティー、製造、ロボティクスをはじめとする、高度な画像理解が求められる場面での活用が見込まれる。また、昨今需要が高まっている基盤モデルの構築とトレーニングのハードルを下げる技術になることも期待される。
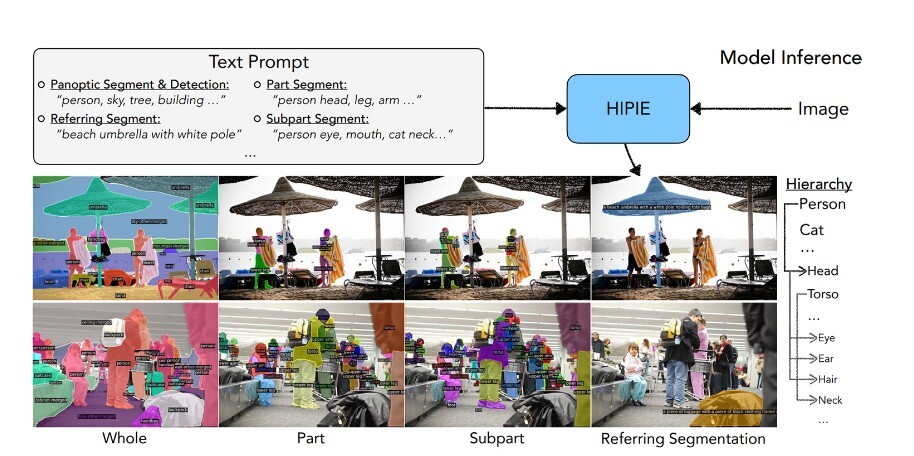
画像とテキストの入力に応じて階層的な画像セグメンテーションを行うHIPIEの出力結果(採択論文から引用)
近年、画像認識AIの構築にかかる時間やコストの削減を見込める手法として、LLMを応用した研究が注目されている。
LLMの事前知識を画像に取り込むに当たって、実際は異なる粒度の階層的な言語(例えば、人→顔→鼻/口/目など)が同一の物体領域に存在する場合、基本的には階層的な関係性は無視され、領域と言語が1対1で対応する形で扱われてきた(人/顔/鼻のどれか一つ、もしくは、「人 顔 鼻」とつなげただけの文字列で学習など)。
パナソニックHDでは、これまで無視されてきた「階層的な関係性」がAIによる高度な画像理解に必要であることに着目し、異なる粒度の階層的な表現を学習する技術を開発した。これにより、これまで階層に応じて複数のモデルを用意する必要があったセグメンテーションや画像認識を1つのモデルで実現できるようにした。
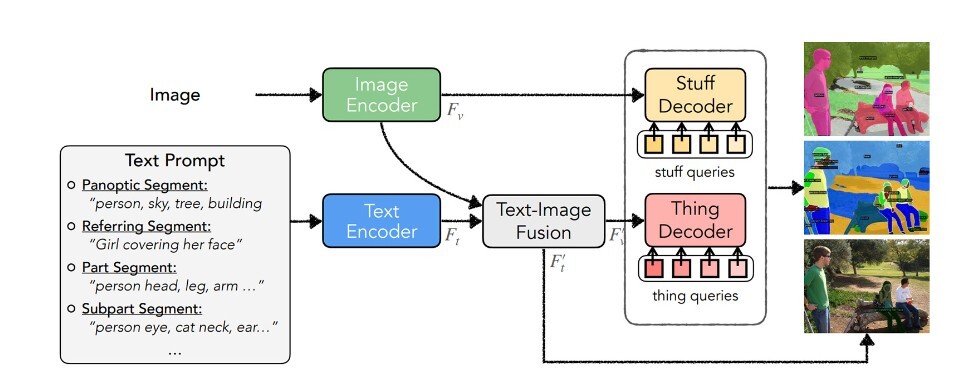
HIPIEの構成図(採択論文から引用)
セグメンテーションや画像認識において、画像中に人物が写っている場合、通常であれば「人」ラベルが割り当てられる。また、タスクによってはその領域に「顔」や「鼻」といった粒度の異なるラベルが割り当てられる必要がある。
このように粒度の異なるラベルを同時に学習する場合「person nose」「dog nose」のようにラベル名をつなげて学習させるのが一般的だ。ただし、この方法で学習したAIは、「giraffe nose」(キリンの鼻)のように未知のテキストが現れると途端にうまく扱えなくなる問題があった。
これに対し、HIPIEではさまざまなスケールを包括することで、所望の画像分割と高度な画像理解を可能にした。これによりモデルの表現能力が格段に向上させ、未知の組み合わせラベルに対応できるようにした。





