GitHubは米国時間9月10日、ファインチューニングモデルを「GitHub Copilot Enterprise」ユーザー向けに限定パブリックベータ版を提供した。同モデルを使用することで、AIプログラミングツール「GitHub Copilot」をユーザー独自のコードベースやコーディング慣習でカスタマイズし、特定のニーズに合わせて関連性、品質、一貫性のあるコード補完支援の向上を提供可能にする。
内部API、特殊なフレームワーク、独自の言語、厳格なコーディングスタイルを使用している組織は、ファインチューニングモデルの恩恵を受けることができるとGitHubは語る。例えば、「COBOL」のようなレガシー言語を使用している金融機関は、ファインチューニングモデルを使って特有のコーディング要件に対応できる。テクノロジーまたはヘルスケア分野では、クラウドリソースが組織の方針に従ってデプロイされているかといったコンプライアンスとセキュリティ基準を順守するため、社内ライブラリーに依存することが多くあるが、コーディングの正確性・効率性を大幅に改善できるという。
また、開発者は、調整の必要が少ないコードを受け取ることができるため、新しいチームメンバーのオンボーディングを迅速化でき、ベテラン開発者も修正ではなく開発により集中できるようになる。より関連性が高く、高品質で一貫性のあるコーディング支援を提供することは、GitHub Copilotを組織にとってさらに役立つツールとするための大きな前進とGitHubはアピールする。
同社では、GitHub Copilotをカスタマイズするための取り組みを続けており、GitHub Copilot Enterpriseでは、リポジトリーインデックスとナレッジベースがまず導入されている。ともに検索拡張生成(RAG)を活用するが、RAGは、チャット体験を最新の出力で改善するのには有効な一方で、リアルタイムでのコード補完で求められるパフォーマンスを満たさないという。今回、ファインチューニングでコード補完体験にカスタマイゼーションが導入されたことで、GitHub Copilotがコンテキストに応じた提案をインラインコーディングで必要な速度で提供できるようになったとGitHubは強調する。
各モデルのカスタマイズには、低ランク近似(Low-Rank Approximation:LoRA)手法が使われる。最も重要なモデルのパラメーターの小さなサブセットを教師あり学習フェーズでファインチューニングすることで、モデルの管理性と効率性を高める。これは、従来のファインチューニング技術に比べてより高速かつ安価な学習方法でもあるという。さらに、ファインチューニングのプロセスは、GitHub Copilotからの提案がどのように対処されているかに関するインサイトも取り入れているため、組織が持つ特定のニーズにモデルがより密接に適合していることを確かにする。
チューニングプロセスには「Azure OpenAI Service」が利用され、学習パイプライン全体でスケーラビリティーとセキュリティを提供する。
プライバシーとセキュリティについて、ユーザーのデータはユーザーのものであり、ほかの顧客のモデルを学習させるために使われることはないと同社は述べる。ユーザーのカスタムモデルは非公開のままで、完全に制御できるという。
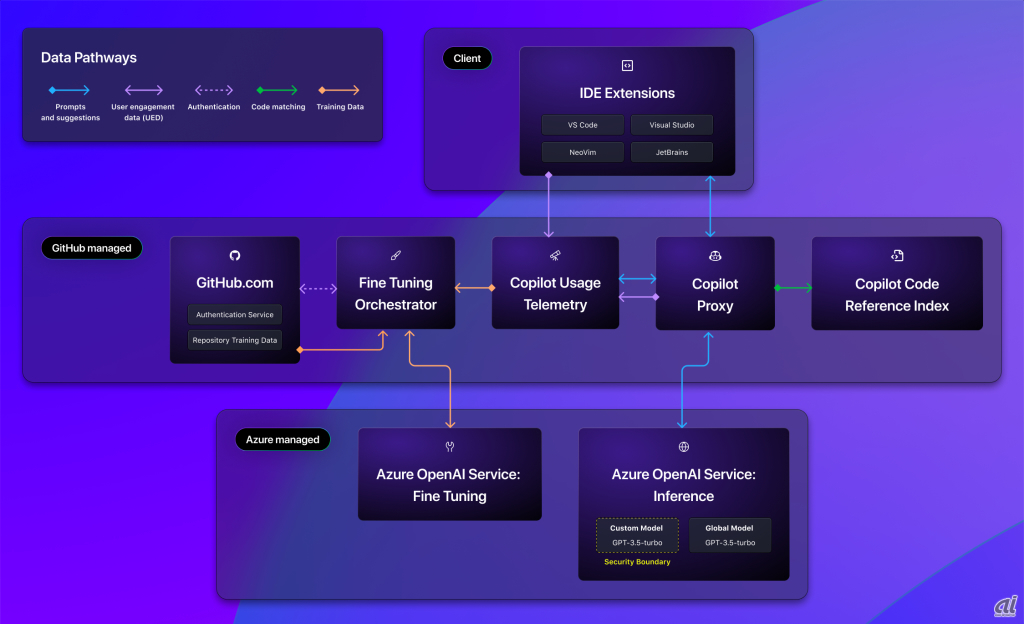
出典:GitHub
学習プロセスを開始すると、レポジトリーデータとテレメトリーデータはトークン化され、一時的にAzureの学習パイプラインにコピーされる。このデータの一部は学習に使われるが、残りは検証と品質評価用に確保される。ファインチューニングプロセスが完了すると、モデルには一連の品質評価が実施され、基本モデルを上回っているかが確認される。これには検証用データに対するテストが含まれ、新しいモデルが、ユーザーのレポジトリー固有なコード提案を改善しているかが確認される。
モデルは、品質チェックに合格すると、Azure OpenAI Serviceに展開される。このステップは、複数のLoRAモデルを大規模にホストすることを可能にする一方で、それらをネットワークで分離することを可能にする。プロセスの完了後、一時的な学習データは全て削除され、データフローは通常の推論チャネル経由で再開される。GitHub Copilotのプロキシーサービスにより、適切なカスタムモデルがコード補完で使われるようになる。
ファインチューニングモデルは現在、限定パブリックベータ版として公開されており、ウィッシュリストから利用を申し込める。





