
スクウェア・エニックスは、モバイルゲーム向けバックエンドシステムの基盤を「Google Cloud」に移行し、より良質なユーザー体験を提供するための体制を確立した。Google Cloudが4月18日に発表した。
Google Cloudへの移行による直接的な効果として、まず水平スケーリングの容易さが挙げられる。従来はAPIの増強に数時間以上かかっていた作業が、「Google Kubernetes Engine(GKE)」では数十秒で完了するため、急激な負荷の増加や負荷試験時のスケール調整に迅速に対応できるようになった。さらに、「Identity and Access Management(IAM)」との高い親和性による権限管理の簡素化、「Cloud Storage FUSE」など既存サービスとの連携、「Cloud Load Balancing」との統合といったGKEならではの利点も実感している。
さらに、従来は一部手作業だったインフラ構築作業が、全てInfrastructure as a Code(IaC)としてコード管理できるようになり、運用の効率化と省力化が実現した。データベースも「Compute Engine」の「InnoDB」クラスター構成に移行したことで、信頼性が大幅に向上した。
約3年にわたる移行作業は2024年9月に完了した。Google Cloudのプレミアムサポートに含まれるテクニカルアカウントマネジメント(TAM)を活用し、予定通り新システムをリリースした。TAMからは、ミッションクリティカルな問題に対する回避策の提案、プロダクト内部仕様を踏まえた対策支援、移行時のバックアップ体制構築、運用上のティップス、中長期的なプロダクト開発計画に関する情報共有など、手厚いサポートを受けた。
現在、移行プロジェクトの第2段階として、データベースを「Cloud SQL Enterprise Plus」へ移行する作業が進められている。既に課金システムを含む一部の重要なシステムでは移行が完了し、その効果が現れている。例えば、バックアップ用レプリカの構築作業は、従来は4人がかりで約3日かかっていたが、Cloud SQL Enterprise Plusでは「Terraform」による自動化により、1人が約1日で完了できるようになり、コストを90%削減した。障害時の復旧も、従来の数時間から、自動フェイルオーバーによりアプリケーション側の変更不要で数十秒での復旧が可能となり、障害時間を99%以上短縮できた。計画停止時間も1秒未満に抑えられ、ユーザー体験を損なわないシステムアップデートが実現した。
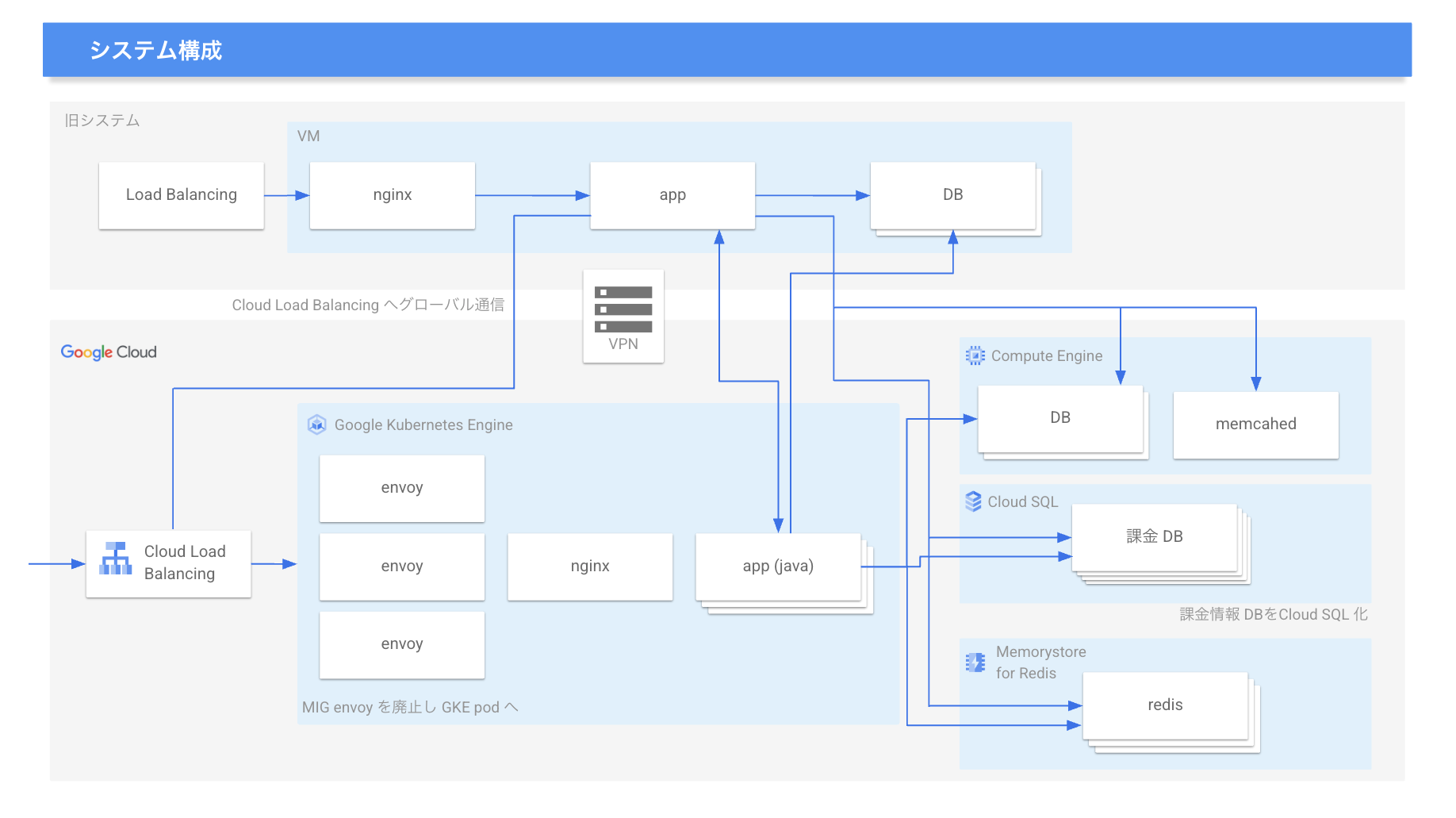
システム構成図(提供:スクウェア・エニックス)
スクウェア・エニックスはこれまで、IaaSに数百台規模の仮想マシンを構築し、モバイルタイトル向けの共通バックエンドシステムを運用してきた。ユーザー情報管理やゲーム内課金機能などを一括して処理し、開発・運用の効率化やコスト削減を図ってきた。しかし、タイトル数やユーザー数の増加に伴い、スケーラビリティーや運用の柔軟性に課題が生じていた。
特にトラフィックが急増する際には、最大で数万リクエスト/秒(rps)のアクセスに対応しながら、数十ミリ秒(ms)単位の応答速度を維持する必要があった。しかし、従来の仮想マシンベースのシステムではスケールアップに時間がかかっていた。また、システム更新に伴う定期的な計画停止はユーザー体験の低下や機会損失につながり、仮想マシン上で運用していた「MySQL」データベースでは障害発生時に復旧まで半日以上かかることもあった。
これらの課題を解決するために、同社はバックエンドシステムのアーキテクチャーを刷新し、コンテナーベースのクラウドに移行することを決定した。複数のサービスを比較検討した結果、Google Cloudを採用することにした。
採用の決め手となったのは、「Kubernetes」のマネージドサービスであるGKEの存在だった。GKEのポッドやノードの自動スケーリング機能により、ワークロードに応じてリソースを柔軟に増減できる点が評価された。また、細かなカスタマイズ性、エンジニアの知識の蓄積のしやすさ、コストパフォーマンス、そしてサービスを停止することなくプラットフォームをアップデートできる点も採用の決め手となった。これらのポイントから、ユーザー体験に影響を与える計画停止を回避できるメリットは大きいと判断された。データベースについては、当初、社内に知識のあるMySQLを継続利用しつつ信頼性を高めるため、Compute Engineを基盤としたInnoDBクラスター構成を採用した。
移行に際して、APIの性能要件を満たすために徹底的なチューニングが行われた。応答速度を改善するために、各APIの通信をパケットレベルで詳細に解析した。これにより、仮想マシン環境とクラウド環境の挙動の違いから生じる性能低下の原因を特定し、設定の見直しや不要な通信の削減などの対策を講じた。このプロセスを通じて、クラウドの内部構造を深く理解し、性能を最大限に引き出すとともに、より堅牢で安定性の高いシステムを構築することができた。





