組織のデータがカオスとなってしまう現状
菅野氏はまず、Talendについて紹介した。TalendはオープンソースのETLソフトウェアのサポートをサブスクリプションで提供する企業として、2006年に創業。その後、狭義のETLの垣根を超え、データ品質、業務アプリケーション連携、Hadoop、Spark連携、クラウド基盤によるSaaS提供と守備範囲を拡大してきた。2016年にはNASDAQに上場し、現在の顧客数は4,750社を超えており、第三者評価機関から業界リーダーとして評価されている。
そして菅野氏は、多くの組織が抱えているデータの処理に関する課題や悩みを紹介した。その背景には、多くのデータシステムとその間を流れる大量のデータが、時間とともに蓄積され続けている、という状況があるが、実際にデータ活用の課題が解決困難になっている根本的な要因は、データの流れ全体を把握する仕組みが不完全であり、また、データを処理するアーキテクチャーに一貫性が欠けているためである、と菅野氏は指摘する。
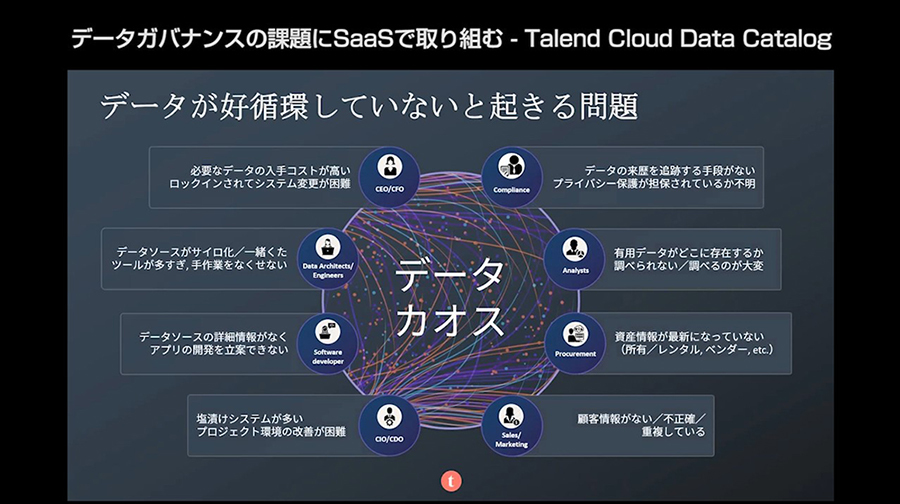
データがカオス状態のときに起きる問題
菅野氏は、データを活用するためのパイプラインを説明した。最初のフェーズは「データを収集し標準化する」、フェーズ2は「データにガバナンスを効かせる」、フェーズ3は「複数のデータを結合し、新しい価値を増やす」、フェーズ4は「新しい価値を共有して活用していく」。そして共有されたデータは、次のサイクルで収集の対象となっていく。このパイプライン処理を循環的に回していくことが、DX(デジタルトランスフォーメーション)を起こすための重要なアプローチといえる。
ガバナンスを効かせた安全なデータで新たなアイデアを生み出す
Talendのデータ統合プラットフォーム「Talend Data Fabric」は、同一プラットフォーム上の複数の機能により4つのフェーズを効率的に回していく。特に、今回の講演のテーマに取り上げた「Talend Data Catalog」は、ガバナンスを効かせるフェーズで重要な役割を担う機能となっている。データにガバナンスを効かせることで信頼性を担保できるので、以降のフェーズでデータの有効性および一貫性について改めて確認する必要がなくなる。
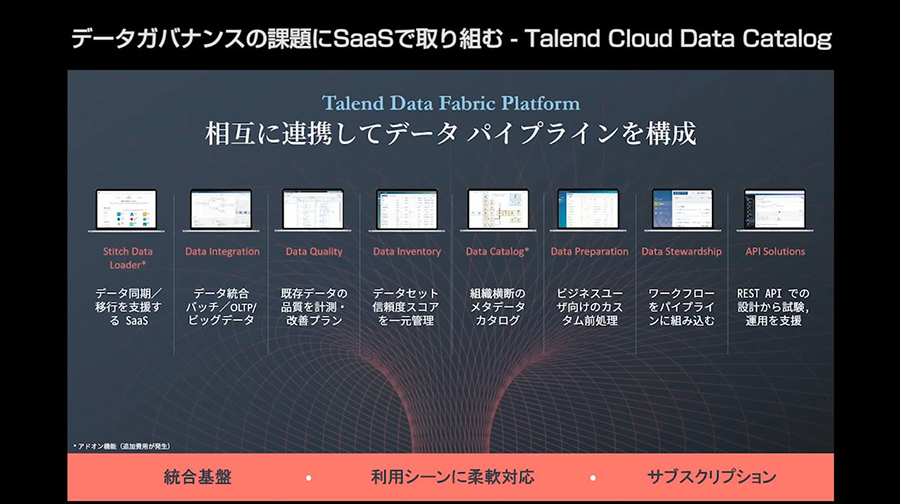
データパイプラインを構成する8つの機能
菅野氏は4つのフェーズについてTalendの特徴を説明した。データの収集と標準化では、さまざまなソースからデータを取得でき、1000種類以上のコネクタが標準で準備されている。データの標準化には定型アルゴリズムが用意されている。アイコンのドラッグ&ドロップで処理を開発できるため、容易にデータ処理・クレンジングを行える。なお「Stitch Data Loader」は、複数データサービス間の同期をブラウザーから簡単にスケジュールできるデータレプリケーションのサービスとなっている。
ガバナンスを効かせるフェーズでは、個人の識別とメタデータ管理が重要となる。メタデータには、データの取得先の情報のほかに、個人情報保護の対象になる情報が含まれている可能性があるため、その管理が重要になってきている。メタデータを活用することで、個人に対するデータ活用の同意確認や、新たなプライバシー保護規制の対応も、迅速かつ統一的な取り扱いが可能になるためだ。
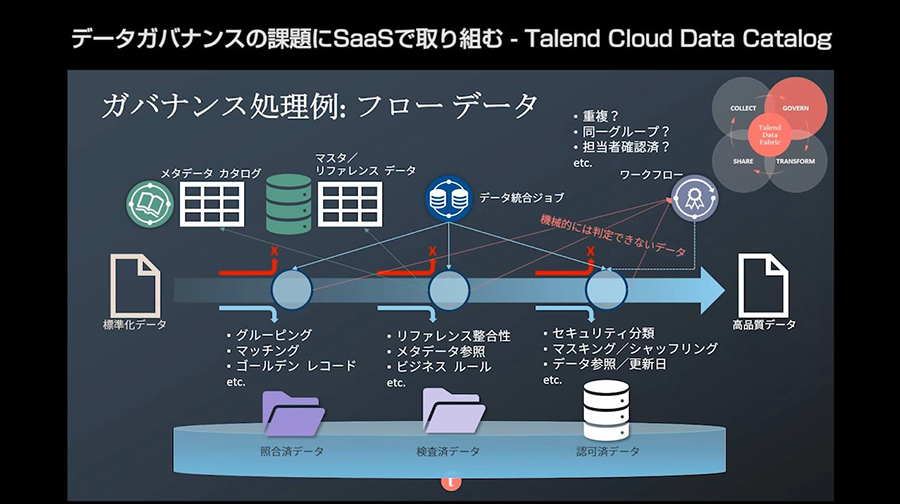
ガバナンス処理のイメージ(フローデータ)
Talendでは、「Data Inventory」によりデータセットの信頼度スコアを一元管理できる。また、マスターデータやゴールデンレコードの作成といった本来は重い処理を、低コストで実現できる。さらに、メタデータを統合管理する「Data Catalog」は、メタデータをカタログとして一元管理することで、組織内のデータの横断検索が可能になる。ここで、テクニカルなメタデータにビジネス用語をマッピングしておくと、直感的に理解できる言葉で検索ができるため、便利に活用できる。
このほかにも、検索したメタデータの来歴や利用先といったリネージをたどる機能も搭載しているので、データ分析の信頼性を高めたり、トラブル発生時の原因を究明したりするといった場面で大いに役立つ。データに関する質問や感想をコメントとして残せたり、見付けた有益な情報を他のユーザーと共有する機能もあるため、組織内のデータ利活用の促進にも有効となる。検索や閲覧に権限を付加することも可能だ。
検索によって得られた情報の意味から探索の範囲を広げていくこともできる。たとえば、「バラの花」について検索したら、次はより一般化して「被子植物」について調べたり、あるいはより具体的な「バラの亜科」について調べていくことで、有益な情報が得られる可能性が拡がる。これにより、新しいビジネスアイデアが生まれる可能性も高まる。Data Catalogはクラウドとオンプレミスの両方で提供される。
データの収集から活用まで一貫したソリューションを提供
データの付加価値を高めるフェーズでは、「端的にいえば、複数のデータを組み合わせ、ビジネスの戦略や優先度に応じてデータを再仕分けしていくことに尽きるといえます」と菅野氏。つまり、結合と分類、その繰り返しであり、Talend製品は結合するデータとしてビッグデータ分析やインターネット上のオープンデータとの連係が豊富であり、またそれらを分類するための定型処理が多数用意されている。
Talendの「Data Preparation」は、付加価値を高めるトランスフォーム段階の、もう一つのデータ変換インターフェイスとなるツール。さまざまなユーザーニーズに基づき、コードを書くことなくデータに最終的な前処理を行うことができる。実施した前処理は、オリジナルのデータに加えたレシピとして保存されるので、レシピを取り消すことでいつでもオリジナルのデータに戻すことができる。Data Preparationはセルフサービス型として提供され、前処理の作業はブラウザーだけで完結する。
新たな価値を共有し活用するフェーズでは、まずは利用者にデータを届けることが重要であるが、Talendは数多くのシステムやデータフォーマットと連携でき、データを届けるタイミングもバッチとリアルタイムの両方に対応している。次に重要な点は、データにアクセスするための敷居を下げること。そしてデータの共有範囲を組織全体に広げていくこととなる。ここでもData Catalogの各種共有機能が大きく寄与する。
ここでは、Data Inventoryがデータを一元管理できるリポジトリーとして機能する。また現在は、実データへのアクセス手段として、REST APIの使用が重要性を増してきている。Talend Data Fabricには、REST APIの設計から自動テストを行うまでの機能が含まれている。APIの定義を作成し、Talendの開発環境でAPIへの処理を実装する「Talend API Designer」と、その試験を行う「API Tester」だ。この組合せにより、処理されたデータやデータ処理自体をREST APIからアクセスする仕組みを、迅速かつ効率的に提供できる。
続いて菅野氏は、Talend Data Fabricのアーキテクチャーについて説明した。ソリューションの基本的なアーキテクチャーは、オンプレミス環境とクラウド環境で大部分が共通になっている。そして、TalendがSaaSとして提供するサーバー環境、お客様が利用する開発環境と実行環境の、大きく3つの要素で構成されている。特徴的なのは実行環境で、クラウドとお客様の環境にまたがったハイブリッド環境になっている。お客様は実行環境を選ぶことができるわけだ。
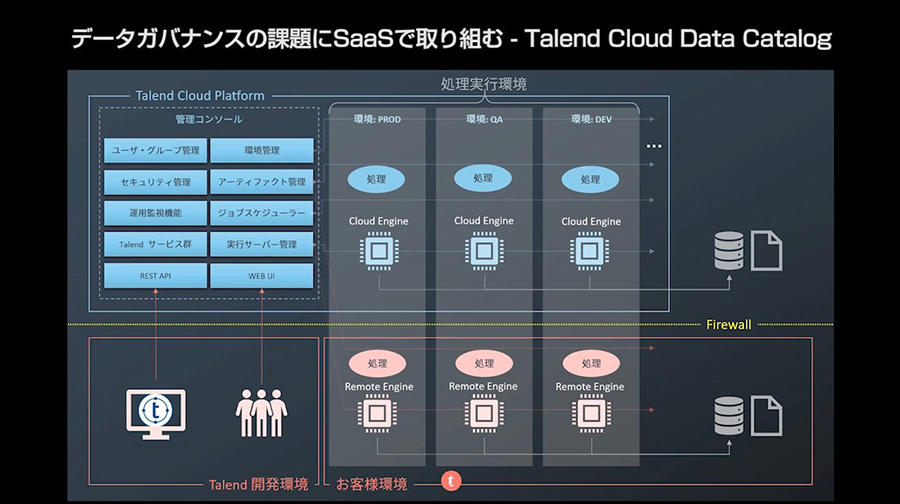
Talend Data Fabricのアーキテクチャー
Talendの導入で年間約110億円のコストを削減
最後に菅野氏は、Talendの導入事例を紹介した。イギリスを本拠地とする製薬会社のアストラゼネカである。アストラゼネカでは、データ処理フローに多くの課題を抱えていたという。たとえば、データ処理にさまざまなツールが使用され、以前に使用されたツールの処理が「地層のように蓄積され、複雑化していた」。手作業が多く介入することになり、その結果データの品質が低下していた。
その影響で財務レポートや年次計画の作成が遅れがちになり、結果として経理業務にかかるコストは常に予算を超過する状況であった。そこで検討を重ねた結果、アストラゼネカはグローバルデータレイクをAWS基盤上で構築することを決定し、そのデータ移行、データ統合およびメタデータ管理の基盤としてTalendのソリューションを全面採用した。
Talendを導入した結果、発生するデータの90%以上は3分以内に分析が可能になった。また、経営層や管理職がウォッチするKPIは自動的に算出されるようになり、各種の管理会計レポートの作成日数も短縮された。月締めの処理は2日短縮され、経理コストは売上げに対して約0.7%まで削減できたという。

AstraZenecaにおけるTalendの導入効果
構築したクラウドデータレイクの容量は20ペタバイトに及んだものの、各システム間はREST APIで疎結合に連携し、また連携システムの数自体が以前より大幅に削減された。アストラゼネカでは、システムのスリム化により、年間約110億円のコスト削減につながった。特に臨床試験に要する時間の大幅な削減が寄与したという。菅野氏は、Talendをうまく使いこなした好例であるとし、講演を締めくくった。