
ビッグデータを加工して「人の流れデータ」を
「人の流れプロジェクト」では、代表的なものとして、国や地方自治体で行ったパーソントリップ調査などで得られたデータを使っている。例えば、首都圏でいえば70万~80万人分の1日の活動情報などである。もともとの調査データは、被験者に配布された、朝、家を出てから、自宅に戻るまでの移動に関する調査票の記述などだ。したがって、このままでは自宅、学校や会社、昼食の場所といった地点や通過時刻の情報と、それぞれの移動手段の情報しかないことになる。
この情報を動線のデータにするには、調査元から許諾を得た上で元データを加工する必要がある。徒歩や交通手段の記述データと地点ごとの緯度、経度情報を合わせ、時間経過に伴う動線をデータ化するわけだ。
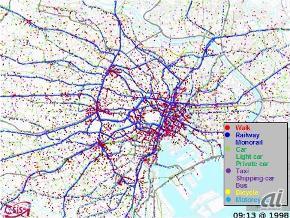
人の動きを解析し、地図上で全体像を把握する
こうした膨大なデータの加工を素早く実行するアルゴリズムを作り出すといったこと、そして、そのアルゴリズムを活用した、使いやすいプラットフォームをいかに構築するかが、関本氏を中心とした研究チームの主要な仕事の1つとなる。
研究者がすぐに利用できるサービス
関本氏によれば、数十万、数百万人単位のデータは内容にもよるが、数ギガから数十ギガにもなり、動線データへの加工は、場合によっては数カ月から1年近くもかかっていた。関本氏のチームでは、一般に市販されているサーバ数台を使ってこの作業を行っていた。
「データ処理に関わるアルゴリズムの開発研究をするのに、1つの作業に長い時間がかかっていては、色々と試行錯誤ができず、研究スピードはいつまでたっても上がりません。そこで2010年ころ、Amazon Web Services(以下、AWS)でAmazon EC2(Amazon Elastic Compute Cloud)を活用してみようということになりました。メモリは4ギガでCPUはノーマルクラスのサーバを数十台という構成で試してみました」(関本氏)
すると、これまで1年近くかかると思われていたデータ加工が、ほんの数日で完了した。もちろん、これまで使っていた既存のマシンの能力から換算して、スピード向上は予測できてはいたが、関本氏が注目したのは、利用の簡便さだ。
「分散処理用に想定した必要分のインスタンスをEC2に作成して利用していますが、データサイズが非常に大きい場合などは、Amazon S3(Amazon Simple Storage Service)を経由して受け渡すこともあります。必ずしも分散処理特有の技術を知らなくても、EC2で利用できる仮想OSイメージである「Amazon Machine Image(AMI)」をコピーし、スケールできることが最低限分かっていれば、学生でもスムーズに利用できます」





