
日本IBMは11月16日、AI(人工知能)基盤「IBM Watson」の技術動向説明会を開催した。「ビジネスのためのAI基盤」をアピールし、Watsonの特徴点や機能強化など、最新の動向について明らかにした。
Watsonは、サービス提供の土台となる「クラウド基盤」を最下層に、「データ層」「AI層」「アプリケーション層」の大きく4つのレイヤで構成されている。「高い拡張性と柔軟性、セキュリティを備え、小さな投資で素早くスモールスタートできるようになっている」(日本IBM 理事 IBM Watsonソリューション担当 元木剛氏)
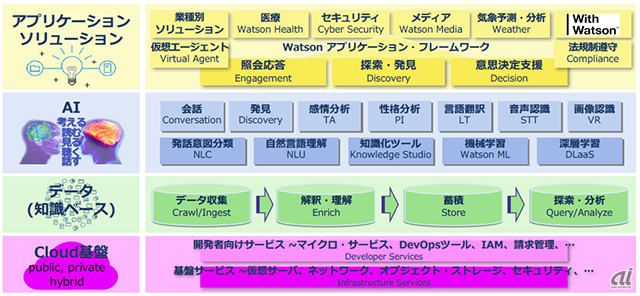
Watsonを構成するサービス群
データ層は、顧客が保有するデータを学習し、個別のAIシステムを開発するための仕組みを用意する。具体的には、知識データベースと専門領域特化モデルを効率良く構築するためのツールを提供する。顧客が構築した環境は「プライベートインスタンス」として管理され、パブリックサービスとは分離される。「顧客の同意なしに他への転用はしない」(元木氏)としている。
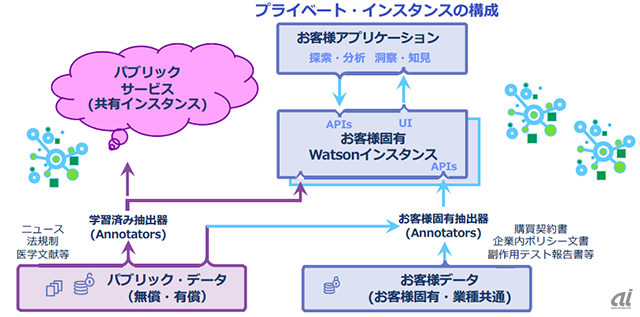
顧客データの活用と保護
AI層は、自然言語処理や機械学習、深層学習などの技術をユースケース別に統合したAPI群。複数の技術を適材適所に組み合わせてアプリケーションに実装することができる。
アプリケーション層は、ビジネスでの実用化事例と学習済みアプリケーションアセットを提供する。短期間でAIシステムを構築するための統合基盤を用意。「照会応答(Engagement」「探索・発見(Discovery)」「意思決定支援(Decision)」という2つのアプリケーションフレームワークを中核として医療、セキュリティ、メディアなどの業種別ソリューションを提供する。
Watsonのコグニティブサービスは、「会話系」「知識探索系」「画像系」「音声系」「言語系」に分けられる。
会話系は、アプリケーションに自然言語インターフェースを追加してエンドユーザーとのやり取りを自動化する「Conversation」、機械学習なしにすぐ利用可能なチャットボット「Virtual Agent」といったサービスで構成される。
Conversationサービスは、機械学習や自然言語解析の技術を使用して対話型アプリケーションを開発するためのプラットフォーム。Intent(意図分類)、Entity(内容抽出)、Dialog(会話)という3つの機能要素を組み合わせて定義されたアクションを実行する。GUIベースの開発運用ツールを提供する。
この半年では、質問の正しい理解や、文脈情報の活用、学習のアシストを向上するための強化が図られている。「実プロジェクトからのフィードバックを基に、日々、機能拡張が実装されている」(元木氏)
知識探索系は、データの隠れた価値を解明して回答やトレンドを発見する「Discovery」、自然言語処理を通じてキーワード抽出・エンティティ抽出・概念タグ付け・関係抽出などを行う「Natural Language Understanding」、ニュースに関する公開データセット「Discovery News」、非構造テキストデータから洞察を取得する「Knouledge Studio」で構成される。
Discoveryサービスは、知識を探索して新たな知見を導き出すコグニティブ技術。営業支援、マーケティング、研究開発、顧客サポート、製造品質、調達購買、経営、法務・知財などの領域で適用可能だとしている。
画像系は、画像コンテンツに含まれる意味を検出する「Visual Recognition」を提供する。画像の認識精度を高めるためのトレーニングツールを用意し、少ない学習データでも高い識別精度を実現できるとしている。
音声系は、音声をテキストに変換する「Speech to Text」、テキストを音声に変換する「Text to Speech」で構成。3月には、米国国防省が提供する業界標準電話音声ベンチマークにおいて誤り率を5.5%まで削減した。
また、最大6人までの話者検出の対応(4月)、医療用語や法律用語などの語彙(ごい)の拡張と業界辞書など独自辞書の登録(7月)、音響モデルのカスタマイズと日本語広帯域での認識精度の向上(10月)など、精度向上と機能拡張を続けている。
深層学習のトレーニング時間を短縮する技術改善も行った。これまでは、10日間のトレーニングで29.9%の精度だったものが、7時間のトレーニングで33.8%の精度が出せるようになった。トレーニング時間の短縮によって、開発期間の錯塩と認識精度の向上を可能にする。
そのほかの直近の施策としては、Watsonを用途別にノウハウをパッケージ化した「AI in a Box」、Watson APIなどのサービスを無償で使える「IBM Cloud ライト・アカウント」なども展開している。





