富士通研究所は、教師データがなくてもデータの特徴を正確に捉える人工知能(AI)技術「DeepTwin」を世界で初めて開発したと発表した。
この技術は、高次元データの削減すべき次元数と次元削減後のデータの分布をディープラーニングで最適化し、データの特徴量を正確に抽出する。これにより、AI分野の重要課題の1つである、データの正確な分布や発生確率の獲得が可能となり、異常データ検知などさまざまなAI技術の判断精度向上に貢献し、幅広いビジネス領域におけるAI適用が期待できる。
今回はデータマイニングの国際学会「Knowledge Discovery and Data Mining」が配布している通信アクセスデータおよびカリフォルニア大学アーヴァイン校が配布している甲状腺数値データや不整脈データといった異なる分野での異常検知のベンチマークでこの技術を検証した。その結果、従来のディープラーニングベースの誤り率と比較して最大で37%改善し、全データで世界最高精度を達成した。
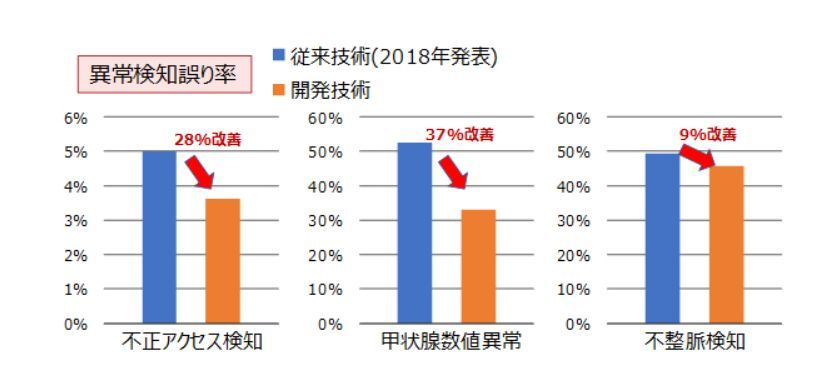
異常検知に同技術を適用した場合の誤り率の改善
通常はAIの学習に大量の教師データが必要となる。しかし。教師データの作成に要する時間や工数などのコストがかかるため、正解ラベルを付与しない教師なし学習の必要性が増している。ただし、通信や画像など扱うデータが高次元の場合は、データの特徴を獲得するのが計算量の観点で困難なため、ディープラーニングを使って入力データの次元を削減する手法が用いられていた。
ところが、この従来の手法では次元削減後の空間における各データの分布や発生確率を考慮せずに削減していたため、入力データの正確な特徴量を捉えきれておらず、AIが誤った判定を行ってしまうといった問題があった。
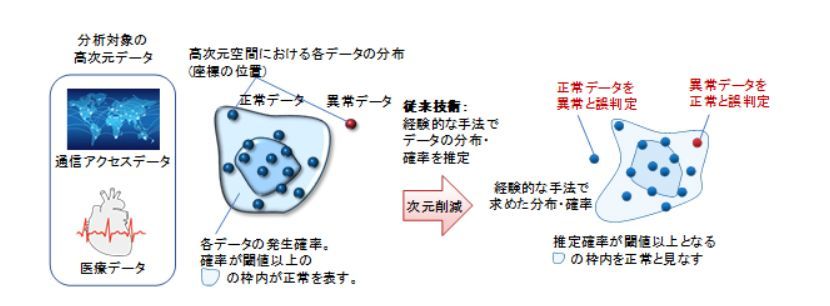
従来の課題(異常検知の例):定量的な裏付けのない経験的な手法のため、誤った判定が発生
DeepTwinでは、最小化したい評価項目を定めると複雑な問題でも評価項目が最小となるパラメータの組合せを求めることができるというディープラーニングの特徴を利用し、高次元データの削除すべき次元数と削除後のデータの分布を制御するパラメータを導入し、圧縮後の情報量を評価項目に定め、ディープラーニングで最適化できるようにしている。これにより、データの特徴を正確に捉えることが可能となった。
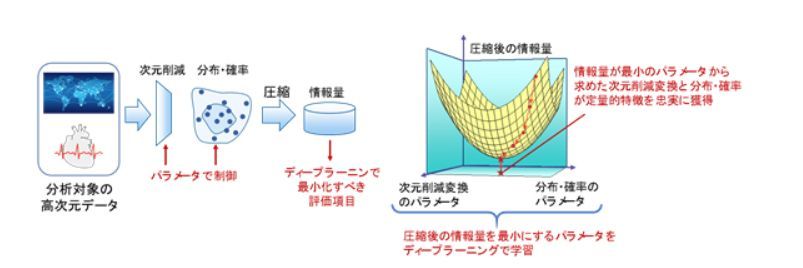
次元削減変換および分布・確率を求めるディープラーニング技術
富士通研究所では、「DeepTwin」により通信アクセスデータや医療データなど、分布・確率が未知の高次元データに対し、その次元をニューラルネットワークの一つであるオートエンコーダーで削減した後、再び復元した時に、元の高次元データと復元後のデータとの間の劣化を一定値に抑えつつ、次元削減後の情報量を最小化したデータは、元の高次元データの特徴を正確に捉え、かつ、次元を最小限に削減できていることを世界で初めて数学的に証明できたーーとしている。
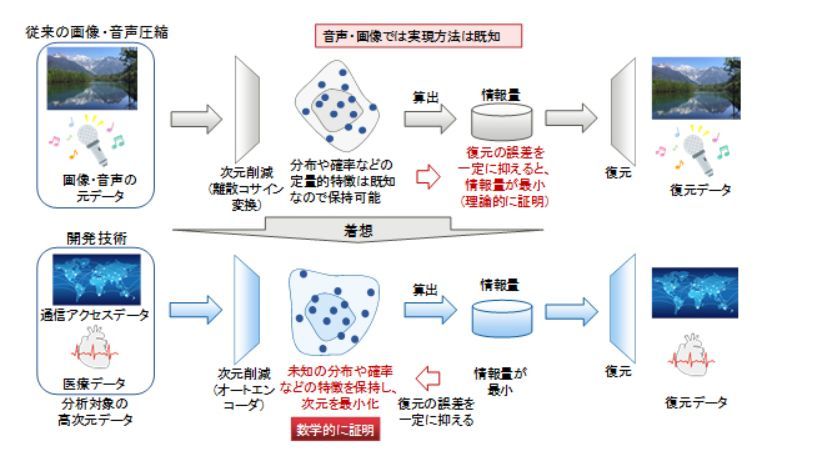
情報圧縮技術に着想を得た、データの特徴に忠実な分布・確率の獲得の理論フレームワーク





