Metaは米国時間7月23日、同社の大規模言語モデル(LLM)ファミリー「Llama」の最新版を発表した。同社によると、「Llama 3.1」は初のオープンソースの「フロンティアモデル」だという。この表現は一般的に、AIコードの模範となる極めて重要な存在に使われるものだ。
Llama 3.1には複数のサイズがある。最大の「Llama 3.1 405B」は、ニューラルの「重み」、すなわちパラメーター数が4050億個で、これはNVIDIAの「Nemotron 4」やGoogleの「Gemma 2」、そして「Mixtral」といった著名なオープンソースモデルを上回るが、405Bで注目すべきはそのコンピューティングの規模だけではない。Metaのチームによる3つの選択という点においても重要だ。
総合的に考えると、その3つの決断はニューラルネットワークエンジニアリングの偉業であり、Llama 3.1 405Bの構築と訓練の根幹を成している。これは、Metaが「Llama 2」で示した深層学習の総演算負荷の削減方法という進歩を補完するものだ。
(「AIモデル」はAIプログラムの一部であり、これに含まれる多数のニューラルネットパラメーターとアクティベーション関数は、AIプログラムが機能する仕組みにおいて重要な役割を果たす)
第1の選択として、Llama 3.1 405Bはいわゆる「混合専門家」を採用していない。混合専門家はGoogleが同社の最新クローズドソースモデル「Gemini 1.5」で、MistralがMixtralモデルで使用している。
混合専門家モデルは、ニューラルの重みのさまざまな代替的組み合わせを作り出す。一部を無効にすることで、重みのサブセットを予測のために使用できるようになる。Metaの研究者らは、「標準的なデコーダーのみのトランスフォーマーモデルアーキテクチャー」を選択した。極めて広い範囲で使用されているこの構成要素は、2017年にGoogleの「Transformer」として最初に開発されたものだ。研究者らは、これによってモデルの訓練中の安定性が向上すると主張している。
第2に、簡素なトランスフォーマーベースのモデルの結果を改善するために、モデルを段階的に訓練する独創的なアプローチを採用した、とMetaの研究者らは説明する。訓練データの量と使用される演算の量の両方を最適な方法で均衡させると、予測の精度を高められることがよく知られている。
Llama 3.1の公式論文に記されているように、研究者らは既存の「スケーリング則」に注目した。この法則から、モデルのサイズと訓練データの量に応じて、どの程度正確な予測が生成されるかが分かる。一方で、標準化された推論テストなど、「ダウンストリーム」タスクを実行するモデルの能力については、このアプローチで正確に知ることはできない。
そこでMetaは独自のスケーリング則を考案した。訓練データの量と演算の量の両方を徐々に増やして、複数の反復をチェックし、訓練済みとなったモデルのダウンストリームタスクの実行能力を確認した。
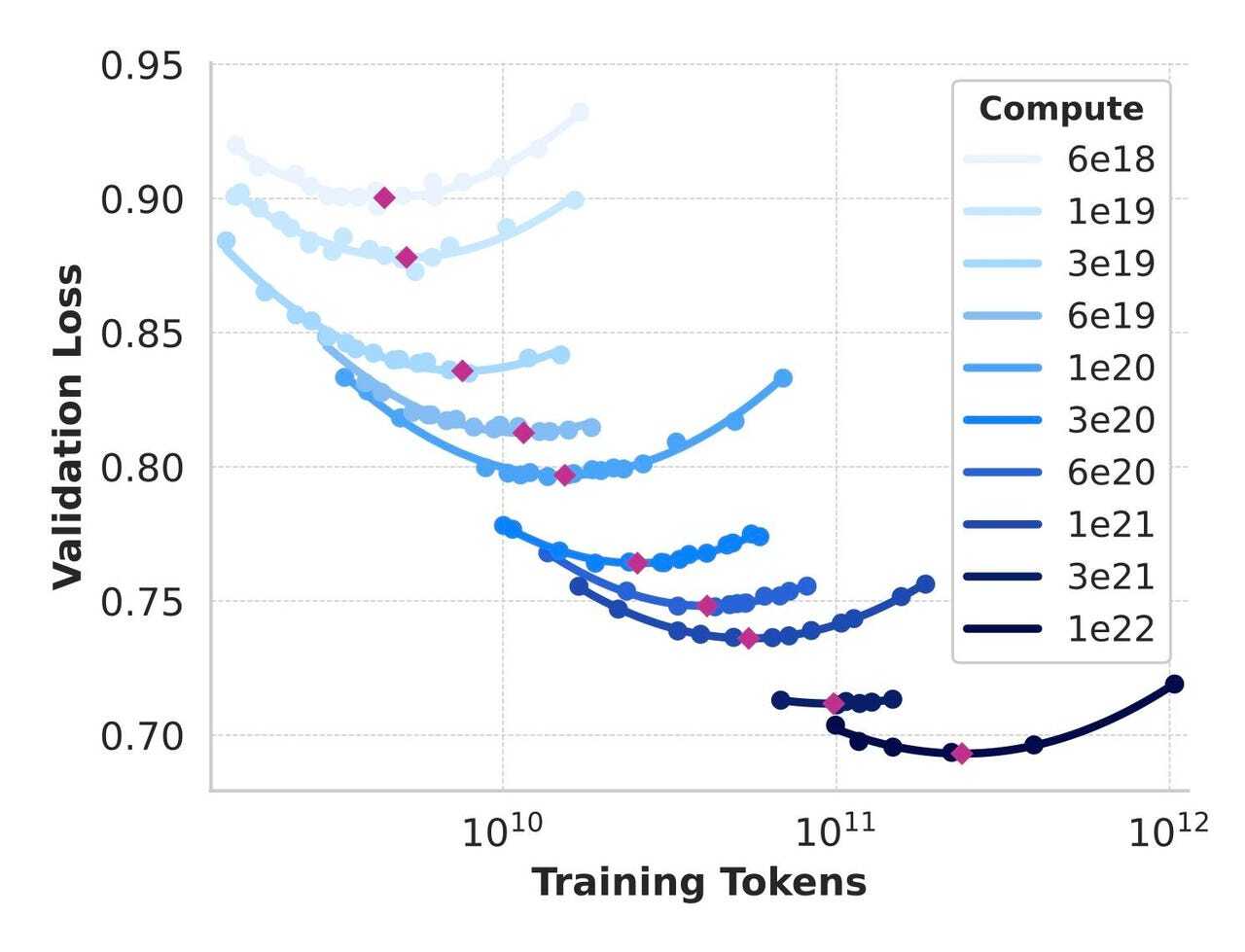
Metaは、演算強度とデータ量のさまざまな組み合わせをテストし、「ダウンストリーム」ベンチマークタスクで最適なパフォーマンスを発揮するスイートスポットを見つけ出した。
提供:Meta Properties
「結果として得られた演算最適化モデルを使用して、ベンチマークデータセットでのフラッグシップLlama 3モデルのパフォーマンスを予測する」とMetaのチームは記している。
これはMetaの最近の研究でみられるアプローチだ。次の単語の予測に関する生のスコアだけでなく、最終的な結果に向けてモデルを訓練する。
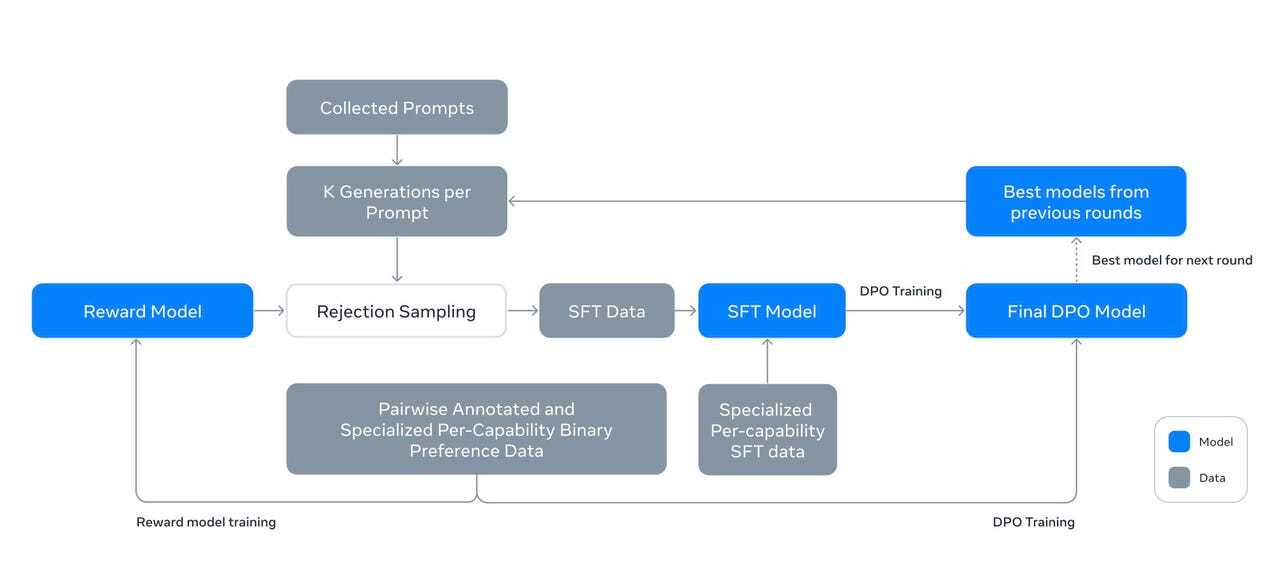
MetaはLlama 3.1 405Bに大規模なポストトレーニングプロセスを実施し、人間からのフィードバックと保持されていた正解例によって微調整した。
提供:Meta Properties
重要なのは、連続するデータと演算の組み合わせの検証を繰り返していくプロセスが、スイートスポットとして選択された4050億のパラメーターへとつながることだ。「この観察結果に基づいて、最終的に4050億のパラメーターでフラッグシップモデルを訓練することに決めた」と研究者らは書いている。





