開催に先立ち、前回のセッションの内容を一部紹介
さっそく、「SharePoint User カンファレンス 2013」の開催に先立ち、前回のセッションの内容の一部紹介だ。まずは、オフィスアイ株式会社の代表取締役であり、Microsoft MVP for SharePoint Server でもある山崎愛氏によるセッション「SharePoint の技術アーキテクチャーの 特性と利点を踏まえた有効活用」だ。
「SharePoint上にある掲示板機能(お知らせリスト)やファイル共有(ライブラリ)などのデータは、Microsoft SQL Serverに格納されます。これはユーザーが手軽にSQL Serverのデータベースを利用できることであり、SharePointサーバーを経由することで擬似的なSQL Server機能を提供していると捉えることもできます。
SharePointは特定の業種、業態を意識することなく、汎用的に利用できる情報共有のシステム。つまり、データ形式指向であるといえます。組織内で共有するデータの形式には、表形式の構造化データと、さまざまな形式の非構造化データがあり、SharePointではそれぞれを「リスト」と「ライブラリ」の2種類のデータ格納方法で管理します。SharePointが得意とするのは、このリストとライブラリを活用した“情報系”システムです」(山崎氏)
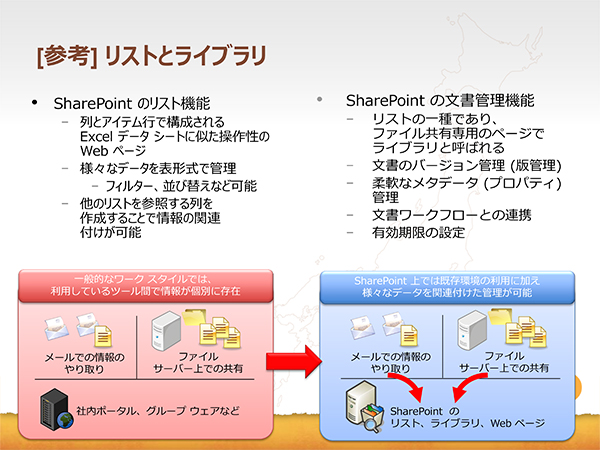
「組織で共有すべきものは、『データ(data)』を『情報(Information)』に整理して蓄積した『知識(Knowledge)』です。そのため、情報共有のプロセスが重要になり、情報の蓄積と再利用 (流通) のスパイラル アップ、蓄積されたデータを色々な角度で収集できるようにすること、情報を構成するデータの性質を吟味し、独立性をできる限り確保することなどが必要になります。そして、組織内のデータをリストやライブラリに分類し、どう関連付けて利用できるようにするかがポイントです。
とはいえ、情報を蓄積する場合、あとから再利用することを考慮して情報共有できるユーザーは非常に少ないのが現状です。リッチテキスト形式でどんどん記述できる方が、データの蓄積速度は速い傾向にあります。ただし、この場合は後から再利用がしにくいという面もあります」(山崎氏)
下の資料1では、SharePointにおけるデータ管理の概念から、情報分類やメタデータ利用時の課題、さらにアクセス権限の考え方にまで踏み込んで解説を行っている。







